Artificial Neural Network (인공신경망)
Artificial Neural network(ANN, 인공신경망)은 상호 연결되어있는 뉴런들의 복잡한 webs로 구성되어있는 생물학적인 학습시스템에서 일부분 영감을 얻었다고 한다. 인간의 뇌는 대략 1011 개의 뉴런(각각 평균적으로 104의 connection을 가진다)의 밀도있게 연결된 네트워크를 가진다고 추정된다. 그리고 그렇게 상호 연결된 뉴런은 시냅스를 통해 신경전달물질을 분비해서 신호를 전달하거나/전달하지 않거나 행동을 취한다.

다음 뉴런을 activation시키기 위해 뉴런에서는 어떻게 결정을 내리는 것일까? 그 rule을 design하는 neural network를 만드려는 여러 시도들이 있고 앞으로의 포스팅에서 차근히 살펴보도록 할 것이다. ANN이 완벽하게 생물학적 모델링을 따르지는 않는다는 점을 먼저 말하고 시작한다. 실제 생물학적 뉴런은 spike의 complex time series를 내보내지만, ANN은 개별 unit이 single constant value를 출력한다.
Perceptron이란 무엇일까?
ANN 시스템 중 한가지 type은 perceptron이라고 불리는 unit을 기반으로 한다. 그러니 perceptron은 neural network를 구성하는 기본 단위라고 할 수 있는 것이다.

perceptron의 구조를 그림으로 나타내 보았다. 여기 나와있는 뉴런은 binary classification을 하는 뉴런으로,
이 과정은 뉴런이 activate되느냐 안되느냐의 과정으로 볼 수 있겠다.
자세히 과정을 하나씩 설명해보면, 일단, 하나의 perceptron은 real-valued input의 벡터를 받게 된다.(넣어준 데이터가 될 수도, 이전 perceptron의 output일 수도) 그리고 이 input들의 linear combination을 계산한다. 그 후 어떤 threshold보다 크면 1 그렇지 않을 경우 -1을 결과로 낸다.

여기서 wi는 real-valued constant이고 weight라고 부른다. xi가 perceptron의 output에 얼만큼 기여하는지를 나타낸다. 그러므로 중요한 xi에 대해서는 더 큰 weight를 줘야한다. threshold값을 x0=1이라는 basis에 어떤 weight를 곱한 값이라고 생각해 넘기면 0보다 큰지 작은지로 식을 general하게 표현가능하다. 그리고 vector form으로 나타내보면 내적으로 나타낼 수 있기 때문에 위의 식을 더 간단히 나타내보면,

where,

예시를 하나 들어보겠다. 우리가 디지털공학시간에 배웠던 OR gate를 perceptron으로 구현하려고 한다.

OR gate와 진리표는 위와 같다. 여기서 input으로 들어가는 x가 A와 B가 되겠고 그에 따른 target output이 나오게 된다. perceptron은 input과 weight의 linear한 combination을 가정하기때문에, 아래와 같이 직선(선형적)을 그려서 두 클래스를 분리할 수 있다. 우리는 두 클래스를 분리하기 위해 아래와 같은 가중치를 생각할 수 있을 것이다.

그러면 두 클래스가 linear하게 잘 분리된 것을 볼 수 있다.

근데 이는 우리가 그냥 그렇게 될 것 같다..하고 정한 weight인데 모든 문제에 대해 우리가 weight를 직접 정할 수는 없을 것 같다는 강한 느낌이 올 것이다. 이제 그럼 이 weight는 어떻게 정해지는가에 대해 의문이 들 수 있다. perceptron을 학습시키는 것이 바로 이 weight들을 선택하는 과정을 포함한다.
Perceptron의 weight는 어떻게 정해지는가?
지금부터 하나의 perceptron을 어떻게 학습시키는지에 대해 이해해볼 것이다. 우리에게 주어진 문제는 perceptron이 주어진 training example들의 각각에 대한 정확한 1인지-1인지의 output을 잘 생성해내도록 weight vector를 결정하는 것이다. 몇몇 알고리즘이 있는데 두가지를 알아볼 것이다. 1)perceptron rule 2)delta rule 이 두가지가 되겠다. 이 두 알고리즘은 다소 다른 조건하에서, 다른 accpetable hypotheses로 수렴하는 것을 보장한다.
두 알고리즘을 살펴보기 전에 간단한 방식으로 weight를 학습시켜보자.
1)Perceptron rule
acceptable한 weight vector를 학습하는 한가지 방법은 random한 weight에서 시작해서 반복적으로 training example에 perceptron을 적용해가며 weight들을 수정하는 것이다. 이 과정은 perceptron이 모든 training exmaple을 정확히 classify할 때까지 계속된다. weight들은 각 step에서 perceptron training rule에 따라 수정된다.

where,
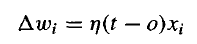
여기서 t는 현재 training example의 target output이다. 그리고 o는 perceptron에서 생성한 output이다. 그리고 η는 learning rate라고 부르는 positive constant이다. learning rate는 아주 작은 값(0.1..)으로 설정한다그리고 때때로 weight를 tuning하는 반복횟수가 증가함에 따라 감소시킨다. 몇가지 예시를 들어보면,
만약에 target t(정답클래스)가 +1인데 perceptron을 거친 output이 +1이면 Δwi가 어차피 0이니 업데이트가 안된다. 그리고 xi가 positive값이라고 하면,
만약에 target t(정답클래스)가 -1인데 perceptron을 거친 output이 +1이면 t-o=-2가 되어 wi가 줄어들게 업데이트 된다.
(다음에 weighted sum이 작아져야 정답클래스인 -1쪽으로 갈 수 있기 때문)
만약에 target t(정답클래스)가 +1인데 perceptron을 거친 output이 -1이면 t-o=+2가 되어 wi가 늘어나게 업데이트 된다.
(다음에 weighted sum이 커져야 정답클래스인 +1쪽으로 갈 수 있기 때문)
사실상 이 학습과정은 finite applications에서 모든 training example들을 올바르게 classify하는 weight vector를 찾을 수 있다고 증명되었다. 단, 조건은 모든 training example들이 linearly separable해야 한다. 만약 linearly separable하지 않다면, 잘 수렴할지 확신할 수 없다.
2)Gradient descent와 delta rule
비록 perceptron rule이 선형적으로 나눌 수 있는 training example에서 성공적인 weight vector를 찾아냈으나, 선형적으로 나눠지지 않아 비선형적으로 모델링해야 하는 경우에는 weight가 제대로 수렴하지 못할 수 있다. 이 두번째 rule인 delta rule은 이런 어려움을 극복하기 위해 design되었다. delta rule 뒤에 숨겨진 key idea는 gradient descent를 이용하는 것이다. gradient descent가 나중에 소개될 backpropagation에서의 basis를 제공하기 때문에 이 rule이 굉장히 중요하겠다. delta training rule은 perceptron이 threshold되지 않은 그냥 linear unit일때 가장 잘 이해가 된다.

위와 같은 결과 값을 낸다고 할때, weight vector의 training error의 measure를 아래와 같이 구체화 해보도록 하자.

가장 쉬운 measure로 squared error를 정의했다. 1/2를 곱하는 것은 미분했을때 2가 생기는 효과를 상쇠시키는 것이다. 나올수 있는 모든 weight에 대하여 E값을 visualize해보면,

이와 같이 그릴 수 있다. 이 그림 보면, 밥그릇을 엎어놓은 것 같이 생겼는데 이런걸 convex function이라고 부른다. error function이 이렇게 convex function을 가진다면 우리는 안심하고 gradient descent 알고리즘 사용할 수 있다. 이 그림의 error surface는 항상 single global minimum값을 가지기 때문! (다른 local minima가 존재하지 않음) gradient descent는 임의의 초기 weight vector에서 시작해 E를 minimize하는 weight vector를 찾는 것이다. 알고리즘을 자세히 살펴보면, 일단 어떻게 error space에서 가장 가파른 경사의 방향을 찾을 수 있느냐?라는 질문으로 시작할 수 있다. 바로 생각할 법한 바로 그 방법,, 미분을 이용하는 것이다. 미분은 기울기라고 고등학교때 배웠던 기억이 있을 것이다.

error surface를 각각 weight들로 편미분할 수 있겠다. 그렇게 편미분한 값을 벡터형태로 위와 같이 나타낼 수 있다. 이 벡터의 element들의 의미는 각 weight에 대해 error surface가 가장 가파르게 경사가 증가하는 방향을 말하게 된다. 그리고 우리는 경사가 반대로 감소하는 방향, 아까 본 error surface가 가장 작은 값을가지는 곳으로 내려가야하기 때문에 음수를 취한 값을 빼주는 방식을 사용할 것이다. 그래서 update rule을 살펴보면 아래와 같다.

where,

여기서 η는 learning rate를 말하는데, 얼마나 조금씩 내려갈 것인지를 설정하는 것이다. 발걸음으로 치면 얼마나 큰 보폭으로 갈 것이냐를 정하는 것이다. 너무 큰 발걸음으로 가게되면 global minima를 지나갈 수도 있고, 너무 작은 발걸음으로 가게되면 너무 느리게 converge할 수도 있다. 이런 training rule을 각 component에 대해 써보면 아래와 같다.

where,

그럼 실제로 미분을 해서 식을 완성해 보자. wi에 대해서 미분을 해보면 아래와 같다.

이 미분값을 이용해서 delta값을 정리해서 아래와 같이 쓸 수 있다.

그래서 지금까지 살펴본 linear unit에서의 gradient descent algorithm을 요약해보면,
- random한 weight vector를 초기값으로 잡는다.
- 모든 training sample에 linear unit을 적용한다.
- 금방 살펴본 delta값을 구해 각각의 weight wi를 update해준다.
- 아까 봤듯이 linear하든 아니든 error surface가 single global minima를 갖기 때문에 이 알고리즘은 error를 minimize하면서 weight vector도 converge할 것이다.
- learning rate가 너무 크면 overstepping할 수도 있다.
- 그래서 한가지 흔한 modified된 방법은 gradient steps이 증가할 수록 learning rate를 줄이는 것이다. 그니까 점점 mimimum값에 가까워질 수록 조심히 조금씩 내려가는 것을 뜻한다.
MLP(Multi-Layer Perceptron)
아까 single perceptron을 이용해 OR gate를 구현할 수 있다는 것을 봤다. OR gate 뿐만 아니고 AND, NAND 또한 하나의 perceptron으로 구현할 수 있다. 근데 XOR을 그래프로 나타내면 아래와 같다.

XOR같은 경우는 linear하게 분리를 할 수 없어서 저렇게 선을 구불구불 그려야한 두 클래스를 분리할 수 있다. 그렇기 때문에 linear하게 분리할 수 없는 XOR은 perceptron하나로 구현할 수 없다. 달리 말하면 single perceptron은 linear한 decision만 할 수 있다는 것이다. 이럴 땐 어떻게 해야할까...? 앞서 살펴본 구했던 gate들을 연결해서 XOR을 구현할 수 있다.

아... 발그림 gate들은 모두 single perceptron으로 만들었기 때문에 perceptron을 여러겹 쌓았다고 볼 수 있겠다. 이를 multi-layer perceptron이라고 하고 이를 이용해 nonlinear한 decision을 할 수 있다.
자 다시 대학교때 디지공시간으로 돌아가서 NAND gate를 이용해서 모든 gate를 구현할 수 있다는 것을 들은 적이 있을 것이다. 아 그렇다.... 우리는 single perceptron으로 NAND를 구현할 수있고, perceptron을 여러개 연결하면 이론적으로 모든 컴퓨터의 연산을 구현할 수 있겠다는 생각을 할 수 있다.
Reference
- Machine Learning - Tom Mitchell
- 밑바닥부터 시작하는 딥러닝
- https://hunkim.github.io/ml/
'ML&DL > Deep Learning' 카테고리의 다른 글
| 더 깊은 네트워크를 위한 Activation function(활성화 함수) (0) | 2020.11.10 |
|---|---|
| Gradient descent algorithm(경사하강법)과 back propagation (0) | 2020.11.10 |

