
(본 포스팅은 이 글 번역 + 마지막에 제 생각을 덧붙였습니다.)
PyTorch는 tensor의 type(형)변환을 위한 다양한 방법들을 제공하고 있다. 몇몇의 방법들은 초심자들에게 헷갈릴 수 있다. 그래서 view() vs reshape(), transpose() vs permute() 에 대해 얘기해보고자 한다.
view() vs reshape()
view()와 reshape() 둘 다 tensor의 모양을 바꾸는데 사용될 수 있다. 그러나 둘 사이에 약간 차이가 있다.
(** 둘 중 어떤 함수를 쓰더라도 데이터의 구조가 변경될 뿐 순서는 변경되지 않는다.)
view() 는 오랫동안 지속된다. 이 함수는 새로운 모양의 tensor를 반환할 것이다. 반환된 tensor는 원본 tensor와 기반이 되는 data를 공유한다. 만약 반환된 tensor의 값이 변경된다면, viewed되는 tensor에서 해당하는 값이 변경된다.
반면에 reshape()는 0.4버전에서 소개된 것으로 보인다. 공식문서에 따르면, reshape()는
Returns a tensor with the same data and number of elements as input, but with the specified shape. When possible, the returned tensor will be a view of input. Otherwise, it will be a copy. Contiguous inputs and inputs with compatible strides can be reshaped without copying, but you should not depend on the copying vs. viewing behavior.
torch.reshape는 원본 tensor의 복사본 혹은 view를 반환한다. 그러니 결국 copy를 받을지 view를 받을지 모른다. 만약 원본 input과 동일한 저장이 필요할 경우, clone()을 이용해서 copy하거나 view()를 이용해야한다고 한다.
x = torch.rand(2, 3, 4) # [2, 3, 4]
y = x.view(2, -1) # [2, 12] x = torch.rand(2, 3, 4) # [2, 3, 4]
x = x.reshape(2, -1) # [2, 12]transpose() vs permute()
permute()와 transpose()는 유사한 방식으로 작동한다. transpose()는 딱 두 개의 차원을 맞교환할 수 있다. 그러나 permute()는 모든 차원들을 맞교환할 수 있다. 예를 들면,
x = torch.rand(16, 32, 3)
y = x.tranpose(0, 2) # [3, 32, 16]
z = x.permute(2, 1, 0) # [3, 32, 16]
알아둬야할 것은, permute()에서 굳이 모든 차원에 새로운 순서를 줄 필요는 없다는 것이다. transpose()에서 특별히 두 개의 차원만 제공하는 것이므로, permute()의 특별한 경우라고 이해하면 된다.
view() vs permute(), transpose()
permute()와 transpose()는 view()와 마찬가지로 tensor의 모양을 바꾸는데 사용할 수 있다. 둘은 연산자체도 차이가 난다. 예시를 통해 보면 view의 경우 순서를 유지하되 다음 차원으로 넘기는 것과 다르게 permute는 transpose연산이 진행된다.
import torch
a = [[1,2,3,4],
[1,2,3,4],
[1,2,3,4]]
a = torch.Tensor(a) # [3, 4]
b = a.view(4, 3) # [4, 3]
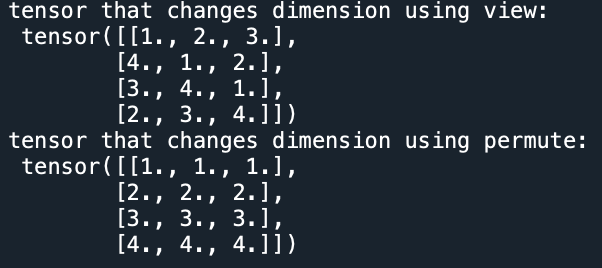
print("tensor that changes dimension using view: \n", b)
c = a.permute(1, 0) # [4, 3]
print("tensor that changes dimension using permute: \n", c)
[결과창]
permute(), transpose()는 view() 와 마찬가지로 역시 원본 tensor와 data를 공유하면서 새로운 tensor를 반환한다. 공식문서에 따르면, transpose()는
Returns a tensor that is a transposed version of input. The given dimensions dim0 and dim1 are swapped.
The resulting out tensor shares it’s underlying storage with the input tensor, so changing the content of one would change the content of the other.
permute(), transpose() 와 view() 의 또한가지 차이점은 view함수는 오직 contiguous tensor에서만 작동할 수 있다는 것이다. 그리고 반환하는 tensor 역시 contiguous하다는 것이다. transpose()는 non-contiguous와 contiguous tensor 둘 다에서 작동할 수 있다. view()와는 다르게 반환되는 tensor는 더이상 contiguous하지 않다. (이말인 즉슨 contiguous하고싶으면 transpose().contiguous()를 꼭 불러줘야된다는 뜻/ permute도 마찬가지)
여기까지 정리를 해보면,
view() vs reshape() 는 연산 자체는 같고 기존 tensor가 변경되냐 되지않냐의 차이가 있는 것이다.
[view(), reshape()] vs [transpose(), permute()] 는 연산 자체도 다르고 출력의 contiguous여부도 차이가 있다.
Contiguous의 의미
Numpy에서의 contiguous에 대한 좋은 대답을 여기서 확인할 수 있다. 이것이 PyTorch에서도 동일하게 적용된다.
내가 이해하기로는 PyTorch에서 contiguous는 아마도 tensor에서 바로 옆에 있는 요소가 실제로 메모리상에서 서로 인접해있느냐를 의미한다. 바로 예시를 들어보자.
x = torch.tensor([[1, 2, 3], [4, 5, 6]]) # x is contiguous
y = x.transpose(0, 1) # y is non-contiguous
tensor x와 y는 동일한 memory space를 공유한다.
print(x.data_ptr()) # 94018404758288
print(y.data_ptr()) # 94018404758288
is_contiguous()를 통해 contiguity를 체크해보면 x는 contiguous하지만 y는 아님을 알 수 있다.
print(x.is_contiguous()) # True
print(y.is_contiguous()) # False
x는 contiguous하기 때문에 x[0][0]과 x[0][1]는 memory에서 이웃하지만 y[0][0]과 y[0][1]은 그렇지 않다.
Contiguous 관련 warning
/opt/conda/lib/python3.8/site-packages/torch/autograd/__init__.py:200: UserWarning: Grad strides do not match bucket view strides. This may indicate grad was not created according to the gradient layout contract, or that the param's strides changed since DDP was constructed. This is not an error, but may impair performance.
grad.sizes() = [64, 64, 1, 1], strides() = [64, 1, 64, 64]
해당 오류는 permute나 transpose사용 시 contiguous()를 쓰지 않아서 생기는 warning이다.
permute(0, 1).contiguous()를 추가해주면 쉽게 해결된다.
출처: https://github.com/pytorch/pytorch/issues/47163
내 생각..
메모리 연속성이 중요하다면 (gpu연산 최적화가 필요하다면) contiguous 중요하고 아니면 괜찮다.
0) reshape과 view는 웬만하면 구분없이 써도 무방할 것 같지만 view를 쓰는게 맘편할지도?

1) [view, reshape]연산과 [transpose, permute]연산은 아예 다르게 작용하기 때문에 feature차원이 아닌 input data차원에서는 어떤게 맞는지 확인하고 경계해서 사용해야 한다.
2) permute를 쓰면 => permute(1, 0, 2).contiguous() 이런식으로 같이 붙여서 써야되는 듯. view를 나중에 쓸 수도 있으니까 대비해서 그냥 permute + contiguous 조합을 차원변경시 시용하자.
3) view는 붙어있는 차원 떼어낼 때 쓰자. [B*2, C, D] -> [B, 2, C, D]
4) 1인 차원 생성/제거할 때는 unsqueeze, squeeze함수를 쓰자.
(squeeze함수를 쓸 때는 없애려는 차원을 꼭 지정하자. 안하면...batch=1일때 Batch가 날라가서 오류날 수 있음)
(22.11.09 추가)
5) 차원관리가 더러우면 einops를 쓰자.
'ML&DL > PyTorch' 카테고리의 다른 글
| [PyTorch] 시계열 데이터를 위한 다양한 Normalization기법 (BatchNorm1d, GroupNorm 사용법) (2) | 2020.07.28 |
|---|---|
| [PyTorch] 시계열 데이터를 위한 1D convolution과 1x1 convolution (11) | 2020.07.08 |
| [PyTorch] torch.nn.KLDivLoss() 사용법과 예제 (1) | 2020.07.07 |
| [PyTorch] numpy에서 tensor로 변환: Tensor, from_numpy함수의 차이/tensor에서 numpy로 변환: numpy함수 (0) | 2020.06.22 |
| [PyTorch] Tensor 자르기/분리하기: chunk함수 (0) | 2020.06.11 |



