
순차적으로 들어오는 정보들의 맥락(context)을 잘 기억하는 딥러닝의 구조로 RNN계열이 있다. 오늘은 RNN이나 LSTM을 처음 사용하는 초심자를 위한 간단한 pyTorch에서의 RNN/LSTM/GRU layer 사용법을 정리한다. RNN 내부 구조보다 input, output의 차원에 초점을 둔 설명이 될 것이다. 그럼 시작!
RNN/LSTM/GRU
먼저 RNN/LSTM/GRU 각각의 cell은 모두 동일한 파라미터를 가지고 있기 때문에 LSTM을 기준으로 PyTorch에서 어떻게 사용하는지 그리고 파라미터는 무엇이 있는 지 하나씩 알아보자.
import torch.nn as nn
lstm = nn.LSTM(input_size, hidden_size, num_layers, bias=True, batch_first=True, dropout, bidirectional)Parameters
- input_size: input의 feature dimension을 넣어주어야 한다. time step이 아니라 input feature dimension!
- hidden_size: 내부에서 어떤 feature dimension으로 바꿔주고 싶은지를 넣어주면 된다.
- num_layers: lstm layer를 얼마나 쌓을지
- bias: bias term을 둘 것인가 (Default: True)
- batch_first: batch가 0번 dimension으로 오게 하려면 이거 설정! 난 이거 설정 가정하고 설명했다. (Default: False)
- batch_first=False라면, (Time_step, Batch_size, Input_feature_dimension) 순서이다.
- batch_first=True라면, (Batch_size, Time_step, Input_feature_dimension) 순서이다.
- dropout: 가지치기 얼마나 할지, generalization 잘안되면 이걸 조정하면 된다.
- bidirectional: 양방향으로 할지 말지 (bidirectional 하면 [forward, backword] 로 feature dimension 2배 됨)
Input
input, (h0) / LSTM 제외
input, (h0, c0) / LSTM만
Input은 입력 sequence와 초기 state (LSTM이면 {hidden state, cell state} 그 외는 {hidden state})로 구성되어있다. 초기 state가 없다면 넣어주지 않아도 되고 자동으로 zero로 설정된다. 입력 sequence의 dimension은 (Batch, Time_step, Feature dimension) 순이다. (batch_first=True 기준)
Convolution은 time_step이 마지막 차원인 것과 차이가 있으므로 두 연산을 이어서 쓸 때는 time_step과 feature dimension의 차원을 swap해서 사용하는 것에 주의하자! 또한 variable length sequence도 사용할 수 있는데 해당 내용은 torch.nn.utils.rnn.pack_padded_sequence() 나 torch.nn.utils.rnn.pack_sequence() 를 참고하자.

Operation
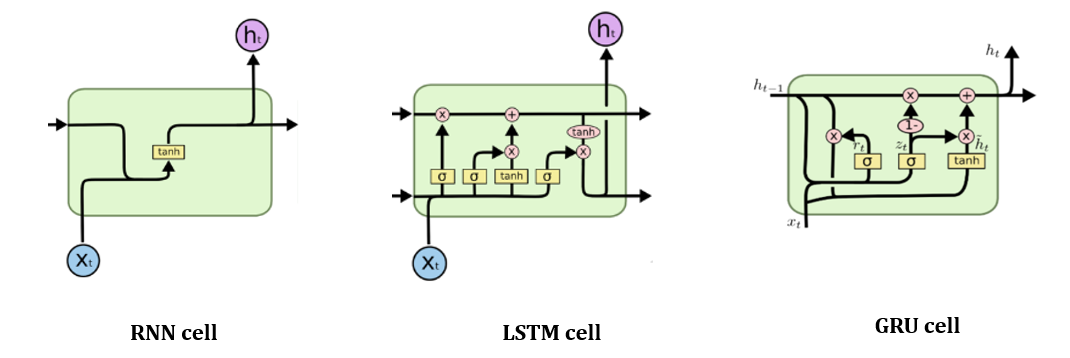
RNN의 연산과정을 통해서 어떻게 마지막 차원이 나오는지 확인해보자. (LSTM과 GRU도 내부연산만 다르고 차원은 같기 때문에 간단한 RNN만 설명하겠다) 너무 어렵게 생각하지 않고 차원 위주로 보면 좋을 것 같다. RNN cell은 하나의 time-step만을 위해 존재한다. RNN은 연산은 time-step의 시작부터 끝까지 순차적으로 진행되면서 이전 time-step의 정보를 반영하는데 이를 hidden state를 이용해서 전달하게 된다. 그래서 각 cell에는 현재 time-step의 입력벡터뿐만 아니라 이전 time-step의 hidden state가 추가적으로 입력된다. 그리고 각 time-step에서는 hidden state을 그대로 혹은 변환하여 다음 layer의 입력 혹은 RNN의 출력을 만든다.

어떻게 각각의 output dimension이 생성되는지를 cell 내부의 연산을 통해 알아보자.
1) Hidden state 계산


2) Output 계산


Outputs
output, (hidden_state) / LSTM 제외
output, (hidden_state, cell_state) / LSTM만
output은 위와 같이 state가 함께 return된다. (LSTM만 cell state있음) 대체로 첫번째 output만 쓴다. (task마다 다르지만) hidden_state와 cell_state는 tuple형태로 return된다.
- output: output dimension은 (time_step, batch, hidden_dimension) 순이다. 양방향일 경우 hidden_size*2
- batch_first=True일 때, (batch, time_step, hidden_dimension)
- hidden state: 모든 layer의 마지막 time_step의 hidden state를 담고있다.
- batch_first=True 로 놓아도 (num_layer*num_direction, batch, hidden dimension) -> 댓글 N'log님의 수정
- cell state: 모든 layer의 마지막 time_step의 cell state를 담고있다. (LSTM만 존재)
- batch_first=True 로 놓아도 (num_layer*num_direction, batch, hidden dimension) -> 댓글 N'log님의 수정
class SingleRNN(nn.Module):
def __init__(self, rnn_type, input_size, hidden_size, dropout=0, bidirectional=False):
super(SingleRNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_direction = int(bidirectional) + 1
self.rnn = LSTM(input_size, hidden_size, 1, dropout=dropout, batch_first=True, bidirectional=bidirectional)
def forward(self, input):
# input shape: batch, seq, dim
output = input
# rnn_out, (h_n, c_n) = self.rnn(output)
rnn_output, state = self.rnn(output)
hidden_state = state[0]
cell_state = state[1]
return rnn_outputRNN, LSTM, GRU 어떤 것을 사용해야 할까?
본인의 task에 맞게 써보면서 고르면 된다. 각각의 특성을 간단히 정리했다.
- RNN: 제일 기본
- LSTM: RNN보다 성능이 좋다고 알려져 있다.(gradient vanishing문제 일부 해소)
- GRU: LSTM보다 빠르다고 알려져 있다.
getattr()를 이용해 RNN type 변경가능하게 하기
실험할 때, 어떤 layer가 좋을 지 모르니까 변경하면서 쓸 수 있도록 설정할 수 있다. 아래의 코드를 이용해 RNN type을 변경하면서 실험해보자.
import torch.nn as nn
rnn_type='LSTM'
lstm = getattr(nn, rnn_type)(60, 20, 1, batch_first=True, dropout=0.2, bidirectional=1)class SingleRNN(nn.Module):
"""
Container module for a single RNN layer.
args:
rnn_type: string, select from 'RNN', 'LSTM' and 'GRU'.
input_size: int, dimension of the input feature. The input should have shape
(batch, seq_len, input_size).
hidden_size: int, dimension of the hidden state.
dropout: float, dropout ratio. Default is 0.
bidirectional: bool, whether the RNN layers are bidirectional. Default is False.
"""
def __init__(self, rnn_type, input_size, hidden_size, dropout=0, bidirectional=False):
super(SingleRNN, self).__init__()
self.rnn_type = rnn_type
self.input_size = input_size
self.hidden_size = hidden_size
self.num_direction = int(bidirectional) + 1
self.rnn = getattr(nn, rnn_type)(input_size, hidden_size, 1, dropout=dropout, batch_first=True, bidirectional=bidirectional)
def forward(self, input):
# input shape: batch, seq, dim
output = input
rnn_output, _ = self.rnn(output)
return rnn_output
Reference
'ML&DL > PyTorch' 카테고리의 다른 글
| [PyTorch] squeeze, unsqueeze함수: 차원 삭제와 차원 삽입 (3) | 2020.09.17 |
|---|---|
| [PyTorch] Tensor 합치기: cat(), stack() (9) | 2020.09.16 |
| [PyTorch] 리눅스환경에서 특정 GPU만 이용해 Multi GPU로 학습하기 (0) | 2020.07.28 |
| [PyTorch] 시계열 데이터를 위한 다양한 Normalization기법 (BatchNorm1d, GroupNorm 사용법) (2) | 2020.07.28 |
| [PyTorch] 시계열 데이터를 위한 1D convolution과 1x1 convolution (11) | 2020.07.08 |



