
Weight decay를 하는 이유
한마디로 말하자면 overfitting을 방지하기 위해 weight decay를 한다. overfitting은 train dataset에 과도하게 맞춰져서 generalization성능이 낮은 것을 의미한다. 그래서 처음 본 test set에서 성능이 안좋게 나오는 경우이다. overfitting을 막고 test set에서도 좋은 성능을 내게 하기 위한 여러 방법들 중 하나가 weight decay이다.
Weight decay와 L2 penalty
Weight decay는 모델의 weight의 제곱합을 패널티 텀으로 주어 (=제약을 걸어) loss를 최소화 하는 것을 말한다. 이는 L2 regularization과 동일하며 L2 penalty라고도 부른다. (L2 regularization은 이 포스팅에서 작동원리를 이해하기 쉽게 설명하였으니 참고바람) 제약은 아래와 같이 dataloss에 패널티텀을 추가하는 방식으로 구현한다. 1/2이 붙는 것은 미분의 편의성을 위함.
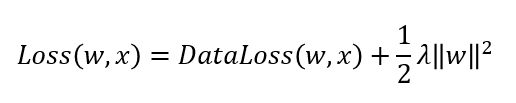
Loss를 미분해보면 아래와 같다.

미분을 했을 때, 기본 dataloss에 w의 lambda배만큼을 더하게 되므로 가중치값이 그만큼 보정된다. 또한 이를 풀어 쓰면 w(1-학습률*lambda)가 되기 때문에 weight가 아주작은 factor에 비례해 감소한다고 하여 weight decay라는 이름으로 불리기도 한다.
Gradient clipping의 pytorch 예제
optimizer의 매개변수로 weight decay value를 넣어줄 수 있는데, 이때 이 값은 앞선 식에서 lambda를 의미한다. lambda값은 하이퍼파라미터로 실험적으로 적절한 값으로 정해주면 된다.
optimizier = torch.optim.Adam(model.parameters(), lr=1e-3, weight_decay=0.9)Reference
'ML&DL > PyTorch' 카테고리의 다른 글
| [PyTorch] PyTorch가 제공하는 Learning rate scheduler 정리 (6) | 2020.12.02 |
|---|---|
| [PyTorch] Dataset과 Dataloader 설명 및 custom dataset & dataloader 만들기 (12) | 2020.09.30 |
| [PyTorch] Gradient clipping (그래디언트 클리핑) (0) | 2020.09.23 |
| [PyTorch] squeeze, unsqueeze함수: 차원 삭제와 차원 삽입 (3) | 2020.09.17 |
| [PyTorch] Tensor 합치기: cat(), stack() (9) | 2020.09.16 |



