
딥러닝 모델을 구축할 때, linear layer, convolution layer 등의 연산 layer뒤에 당연스럽게 activation function을 사용하는 것을 볼 수 있다. activation을 쓰지 않으면 layer를 계속 쌓아도 결국 하나의 layer를 쌓은 것과 다르지 않기 때문에 deep learning에서 activation은 중요한 역할을 한다. 현재 딥러닝 모델은 점점 더 커지고 깊어지고 있기 때문에 activation function은 더 깊은 모델을 잘 학습시킬 수 있게 gradient vanishing 문제를 극복하도록 발전하고 있다. 본 포스팅에서는 먼저 activation function이 무엇인지 간단히 설명하고 상황별 activation 사용법에 대해 요약한 뒤 PyTorch에서 제공하는 activation function을 고전부터 비교적 최근에 제안된 것들까지 소개해보겠다. 그럼 시작!
Activation function 이란?
Activation function(활성화 함수)는 말그대로 뉴런을 활성화하는 함수를 뜻한다. 활성화라는 것은 뉴런을 켜는 것을 말한다. 간단한 step function을 activation function으로 예를 들어보자. fully-connected layer내의 출력노드 하나의 연산은 아래의 그림으로 나타낼 수 있는다. 출력노드는 입력노드들의 weighted sum으로 결정된다. 여기서 activation function을 거치게 되면 출력노드의 값에 임의의 threshold를 정해 그 값보다 크면(=정보가 많다) 통과시키고 작으면(=정보가 적다) 값을 0으로 만들어 노드를 비활성화할 수 있다. 그러므로 activation function은 일종의 logical gate라고 말할 수 있다.

상황별 Activation function 사용법
Activation function도 TPO (Time, Place, Operation(!))에 맞게 사용해야 한다. 상황에 따라 써야하는 activation function의 가이드를 간단하게 정리하였으니 어떤 activation function을 써야할 지 모를 때 아래를 참고하면 좋겠다. 하지만 이 또한 일반적인 경우를 위한 참고일 뿐 자신의 문제에 맞는 activation function을 찾아야할 수도 있다.
Hidden layer
연산에 따라 hidden layer에서의 activation function을 다르게 선택해야 한다.
- Multi-layer perceptron: ReLU 계열
- Convolution neural network: ReLU 계열
- Recurrent neural network: sigmoid / Tanh
Output layer
task에 따라 activation을 다르게 선택해야 한다.
- Regression: 출력노드는 1개로 설정 + Linear activation
- Binary classification: 출력노드는 1개로 설정 + Sigmoid
- Multi-class classification: 출력노드는 class개수로 설정 + Softmax
How to use activation function in PyTorch?
activation function은 사용법이 매우 간단하다. block단위 모델링을 할 때, PyTorch에서 제공하는 activation모듈을 init에서 선언하고 forward에서 연산역할을 하는 layer (dense(=fully-connected, linear), convolution, recurrent) 뒤에 붙여주면 된다. 연산과 activation function은 대부분 같이 다니기 때문에 block형태로 함께 데리고 다니게 코드를 짜면 좀 편하게 쓸 수 있다. (block에 activation도 매개변수로 받으면 activation function도 바꿔가면서 쓸 수 있는데 나중에 심심하면 코드 추가해두겠다..)
import torch
import torch.nn as nn
class DenseBlock(nn.Module):
def __init__(self, in_dim, out_dim):
super(DenseBlock, self).__init__()
self.dense = nn.Linear(in_dim, out_dim)
self.relu = nn.ReLU() # activation function
def forward(self, x):
out = self.relu(self.dense(x))
return out
class OurModel(nn.Module):
def __init__(self, in_dim, hidden_dim, out_dim):
super(OurModel, self).__init__()
self.linear1 = DenseBlock(in_dim, hidden_dim)
self.linear2 = DenseBlock(hidden_dim, out_dim)
def forward(self, x):
out = self.linear1(x)
out = self.linear2(out)
return out
if __name__ == "__main__":
x = torch.rand(500, 128) # The number of traning sample=500
model = OurModel(in_dim=128, hidden_dim=64, out_dim=1)
y = model(x)
print(y.shape)
아니면 torch.nn.functional을 이용해서 init에서 따로 정의하지 않고 함수로 activation function을 쓸 수 있다. (개인적으로 나는 이 방식을 지양했으면 좋겠다. 이 방식으로 activation을 사용할 경우, 모델에서 activation이 달라져도 다른 모델로 인식이 되지 않는다. nn으로 init에서 먼저 define하고 쓰기를 권장한다.)
import torch
import torch.nn as nn
import torch.nn.functional as F
class OurModel(nn.Module):
def __init__(self, in_dim, hidden_dim, out_dim):
super(OurModel, self).__init__()
self.linear1 = nn.Linear(in_dim, hidden_dim)
self.linear2 = nn.Linear(hidden_dim, out_dim)
def forward(self, x):
out = F.relu(self.linear1(x)) # activation
out = F.relu(self.linear2(out)) # activation
return out
if __name__ == "__main__":
x = torch.rand(500, 128) # The number of traning sample=500
model = OurModel(in_dim=128, hidden_dim=64, out_dim=1)
y = model(x)
print(y.shape)PyTorch가 제공하는 activation function들
Sigmoid
ReLU가 등장하기 전에 널리 쓰이던 활성화함수다. 출력이 0과 1사이로 나와 층을 깊이 쌓으면 gradient vanising 문제가 있고 computational cost가 높다. 요새는 hidden layer에는 잘 사용하지 않고 binary classification을 위해 모델의 마지막 output에 적용하거나 아니면 gating mechanism에 활용되는 함수이다.
**값의 범위: [0, 1]


import torch
import torch.nn as nn
class DenseBlock(nn.Module):
def __init__(self, in_dim, out_dim):
super(DenseBlock, self).__init__()
self.dense = nn.Linear(in_dim, out_dim)
self.act = nn.Sigmoid() # activation function
def forward(self, x):
out = self.act(self.dense(x))
return outShape
- Input: 차원은 마음대로 (element-wise operation)
- Output: 입력차원과 출력차원의 수가 같음
Parameters
- X
Tanh (Hyperbolic tangent)
Tanh함수는 zero-centric함수로 sigmoid가 [0, 1]범위에서 [-1, 1]범위로 shift된 형태를 띈다. sigmoid보다 gradient값이 커 loss function을 더 빨리 minimize할 수 있다. 하지만 이 역시 gradient vanishing 문제가 있어 현재는 hidden layer의 activation function으로 잘 사용되지 않는다.
**값의 범위: [-1, 1]


import torch
import torch.nn as nn
class DenseBlock(nn.Module):
def __init__(self, in_dim, out_dim):
super(DenseBlock, self).__init__()
self.dense = nn.Linear(in_dim, out_dim)
self.act = nn.Tanh() # activation function
def forward(self, x):
out = self.act(self.dense(x))
return outShape
- Input: 차원은 마음대로 (element-wise operation)
- Output: 입력차원과 출력차원의 수가 같음
Parameters
- X
SoftPlus
SoftPlus함수는 아래의 식으로 정의된 activation function으로 도함수가 sigmoid라는 특징을 가지고 있다. sigmoid나 tanh와 다르게 unbounded above라는 특징이 있다.
**값의 범위: [0, ∞]


import torch
import torch.nn as nn
class DenseBlock(nn.Module):
def __init__(self, in_dim, out_dim):
super(DenseBlock, self).__init__()
self.dense = nn.Linear(in_dim, out_dim)
self.act = nn.SoftPlus() # activation function
def forward(self, x):
out = self.act(self.dense(x))
return outShape
- Input: 차원은 마음대로 (element-wise operation)
- Output: 입력차원과 출력차원의 수가 같음
Parameters
- beta: Softplus식의 value (default: 1)
- threshold: 이 값 이상은 선형함수로 돌아감 (default: 20)
ReLU (Rectified Linear Unit)
ReLU는 현재 hidden layer의 activation function로 가장 많이 사용되는 함수이다. ReLU는 간단하고 계산이 효율적이라는 장점이 있다. (sigmoid, tanh보다 SGD에서 수렴속도가 6배 빠르다고 함) 또한 입력이 0보다 클 경우 입력이 그대로 나가기 때문에(unbounded above) gradient vanishing 문제에서도 이전 activation function보다 낫다. 그리고 원치 않는 노드를 꺼버리는 역할을 하기 때문에 효율적인 학습이 가능하다.
**값의 범위: [0, ∞]

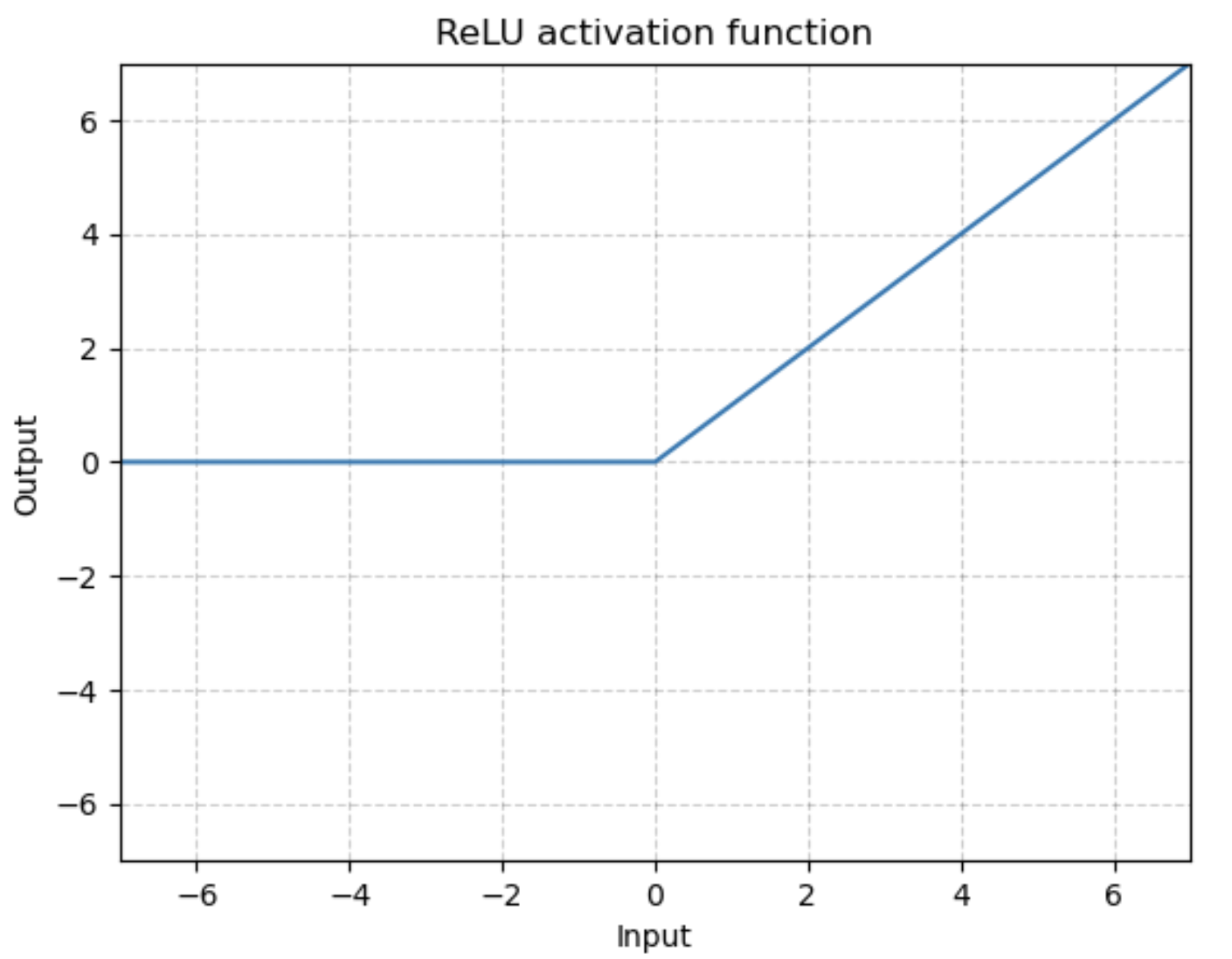
import torch
import torch.nn as nn
class DenseBlock(nn.Module):
def __init__(self, in_dim, out_dim):
super(DenseBlock, self).__init__()
self.dense = nn.Linear(in_dim, out_dim)
self.act = nn.ReLU() # activation function
def forward(self, x):
out = self.act(self.dense(x))
return outShape
- Input: 차원은 마음대로 (element-wise operation)
- Output: 입력차원과 출력차원의 수가 같음
Parameters
- inplace: (default: False)
- inplace=True로 설정할 경우, 입력을 따로 저장하지 않고 바로 operation을 진행하기 때문에 메모리를 소량 절약할 수 있다. 대신 원본 입력이 destroy되는 점을 주의해서 사용해야 한다.
ReLU's varients
ReLU가 이전 activation function들보다 gradient vanishing 문제에서 자유롭지만 드물게 neural net 전역에서 노드가 모두 0이 되어버려 기울기를 0으로 만드는 현상을 발생시킬 수 있어 파라미터가 업데이트 되지 않는 현상을 야기할 수 있다. gradient vanishing을 극복하기 위해 음수정보를 가져가는 방식으로 ReLU의 변형들이 많이 등장하였다.

1. Leaky ReLU
Leaky ReLU는 ReLU가 0보다 작은 구간에서 아예 0이 되지 않게 하기 위해 아주 약한 음의 기울기를 주는 방식으로 ReLU의 단점을 보완하고자 하는 activation이다. 하지만 이 방법은 bounded below되어있지 않기 때문에 음수곱의 누적으로 feature가 잘 activation되지 않을 수도 있다는 단점과 ReLU 보다 연산이 복잡하다는 단점이 있다.
**값의 범위: [-∞, ∞]


import torch
import torch.nn as nn
class DenseBlock(nn.Module):
def __init__(self, in_dim, out_dim):
super(DenseBlock, self).__init__()
self.dense = nn.Linear(in_dim, out_dim)
self.act = nn.LeakyReLU() # activation function
def forward(self, x):
out = self.act(self.dense(x))
return outShape
- Input: 차원은 마음대로 (element-wise operation)
- Output: 입력차원과 출력차원의 수가 같음
Parameters
- negative_slope: 음수구간에 대해서 음의 기울기를 주는데 이때 기울기의 각도 (default: 1e-2)
- inplace: (default: False)
2. ELU
ELU는 ReLU가 음의 값에서 0이 되는 문제를 아래의 formulation으로 해결한다. ReLU가 구간별 선형성을 가지는 것과 달리 smooth한 곡선으로 미분이 가능하고 비선형성을 더 잘 모델링한다. ReLU, LeakyReLU보다 좋은 성능을 보인다고 저자가 실험을 통해 증명했다.
**값의 범위: [-α, ∞]



import torch
import torch.nn as nn
class DenseBlock(nn.Module):
def __init__(self, in_dim, out_dim):
super(DenseBlock, self).__init__()
self.dense = nn.Linear(in_dim, out_dim)
self.act = nn.ELU() # activation function
def forward(self, x):
out = self.act(self.dense(x))
return outShape
- Input: 차원은 마음대로 (element-wise operation)
- Output: 입력차원과 출력차원의 수가 같음
Parameters
- alpha: ELU 식에서의 value(Default: 1.0)
- inplace: (Default: False)
3. GELU
GELU는 Gaussian Error Linear Unit의 줄임말로 원본입력에 원본입력을 Gaussian distribution의 CDF를 통과한 값과 곱해주는 함수이다. 이를 통해 x가 다른 입력과 비교했을 때 얼마나 큰지로 gating이 되는 효과를 얻는다. 또한 bounded below가 되어있어 gradient vanishing에서 자유롭다. ReLU, ELU와 GELU를 비교했을 때 GELU가 일관적으로 성능이 더 좋다는 실험 결과가 있다. 최근 NLP (BERT 등)와 Vision 분야(Vision Transfoemer 등)가 점점 더 모델이 커지고 깊어지면서 GELU activation을 많이 사용하고 있다.


import torch
import torch.nn as nn
class DenseBlock(nn.Module):
def __init__(self, in_dim, out_dim):
super(DenseBlock, self).__init__()
self.dense = nn.Linear(in_dim, out_dim)
self.act = nn.GELU() # activation function
def forward(self, x):
out = self.act(self.dense(x))
return outShape
- Input: 차원은 마음대로 (element-wise operation)
- Output: 입력차원과 출력차원의 수가 같음
Parameters
- X
SiLU (Swish)
SiLU는 Sigmoid Linear Unit의 줄임말로 원본 입력에 sigmoid를 씌운 값의 곱으로 이루어져있다. 구글이 논문에서 Swish라는 함수로 정의하여서 Swish라고도 부른다. 이 방법 GELU와 마찬가지로 gating을 활용하여 0보다 작은 곳에서 0이 되지 않게 하면서도 bounded below를 한 함수이다.

β 를 조절하며 실험하고 싶다면 다음 함수를 구현해서 쓰면 된다.



import torch
import torch.nn as nn
class DenseBlock(nn.Module):
def __init__(self, in_dim, out_dim):
super(DenseBlock, self).__init__()
self.dense = nn.Linear(in_dim, out_dim)
self.act = nn.SiLU() # activation function
def forward(self, x):
out = self.act(self.dense(x))
return outShape
- Input: 차원은 마음대로 (element-wise operation)
- Output: 입력차원과 출력차원의 수가 같음
Parameters
- X
Mish
Mish함수는 다음과 같은 식으로 gating을 하는 함수이다. GELU나 Swish와 마찬가지로 unbounded above, bounded below의 형태를 가지고 있다. ReLU나 Swish보다 훨씬 손실환경을 더 부드럽게 만든다고 논문의 저자는 소개한다. 이를 통해 더 안정적인 학습이 가능하다.
**값의 범위: [-0.31, ∞]


import torch
import torch.nn as nn
class DenseBlock(nn.Module):
def __init__(self, in_dim, out_dim):
super(DenseBlock, self).__init__()
self.dense = nn.Linear(in_dim, out_dim)
self.act = nn.Mish() # activation function
def forward(self, x):
out = self.act(self.dense(x))
return outShape
- Input: 차원은 마음대로 (element-wise operation)
- Output: 입력차원과 출력차원의 수가 같음
Parameters
- X
Reference
PyTorch documentation:https://pytorch.org/docs/stable/nn.html
Activation function의 전반적 이해:https://mlfromscratch.com/activation-functions-explained/#/
'ML&DL > PyTorch' 카테고리의 다른 글
| [PyTorch] AttributeError: 'str' object has no attribute '_apply' 해결 (0) | 2023.07.12 |
|---|---|
| [PyTorch] 코드 재현성(reproducibility)을 위한 랜덤시드 설정 (0) | 2022.10.19 |
| [PyTorch] BrokenPipeError: [Errno 32] Broken pipe 해결 (2) | 2021.02.02 |
| [PyTorch] PyTorch가 제공하는 Learning rate scheduler 정리 (6) | 2020.12.02 |
| [PyTorch] Dataset과 Dataloader 설명 및 custom dataset & dataloader 만들기 (12) | 2020.09.30 |



