** 본 포스팅은 NeurIPS2021의 self-supervised learning 튜토리얼에 필자의 소소한 설명을 덧붙인 글입니다.
Supervision을 위한 대량의 labelled data 특히 high-quality의 labelled data를 얻는 것은 비용이 많이 든다. unlabelled dataset만으로 task-agnostic하게 데이터를 잘 표현하는 '좋은 representation'을 얻으면 얼마나 좋을까? "unsupervised learning을 통해 좋은 representation을 얻는다면 다양한 downstream task에 빠르게 적응할 수 있을 것이다, 더 나아가서는 supervision보다 더 좋은 성능을 얻을 수 있을 것이다" 라는 생각에서 self-supervised learning 연구들은 출발한다.
Self-supervised learning 이란?
Self-supervised learning은 unlabelled dataset으로부터 좋은 representation을 얻고자하는 학습방식으로 representation learning의 일종이다. unsupervised learning이라고 볼수도 있지만 최근에는 self-supervised learning이라고 많이 부르고 있다. 그 이유는 label(y) 없이 input(x) 내에서 target으로 쓰일만 한 것을 정해서 즉 self로 task를 정해서 supervision방식으로 모델을 학습하기 때문이다. 그래서 self-supervised learning의 task를 pretext task(=일부러 어떤 구실을 만들어서 푸는 문제)라고 부른다. pretext task를 학습한 모델은 downstream task에 transfer하여 사용할 수 있다. self-supervised learning의 목적은 downstream task를 잘푸는 것이기 때문에 기존의 unsupervised learning과 다르게 downsream task의 성능으로 모델을 평가한다.
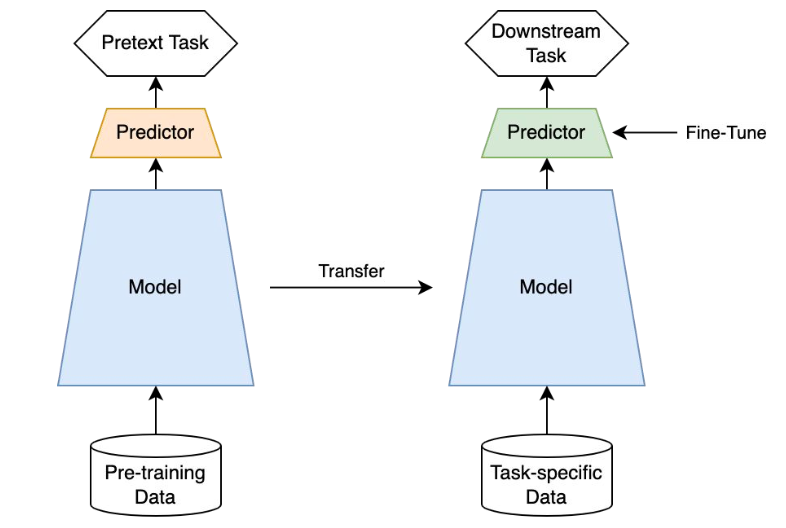
Methods
Self-supervised learning은 큰 카테고리로 보면 Self-prediction과 Contrastive learning으로 나눌 수 있다.
Self-prediction
하나의 data sample내에서 한 파트를 통해서 다른 파트를 예측하는 task를 말한다.

Contrastive learning
batch내의 data sample들 사이의 관계를 예측하는 task를 말한다.

**두 샘플 사이의 관계를 학습하는 방식은 multiview learning에서 기원한 것이다. multiview learning은 같은 class를 가지는 두 샘플(positive samples)간의 공통 부분(=identity를 보여주는 부분=중요한 부분)을 학습하기 위한 방식이었다. 대표적으로 CCA(Canonical Correlation Analysis)를 예로 들 수 있다. 이런 방식들은 Siamese network를 기반하고 있으며, representation collapse라는 치명적 문제를 가지고 있어 이를 극복하기 위해 negative sample을 갖는 contrastive learning(SimCLR, MoCo등)으로 발전하거나 EMA(Exponential Moving Average)기반 Teacher-student 구조를 갖는 모델들(BYOL, DINO, SimSiam등)로 발전했다. 그러므로 contrastive learning은 관계를 학습하는 방식인 multiview learning의 subset으로 볼 수 있다. (contrastive learning 파트에서 설명 예정)
Self-prediction
앞서 설명한 것처럼 개별 샘플 내에서 데이터의 일부를 이용해 나머지를 예측하는 task를 말한다. 예를 들어 time-series의 경우 next time step을 예측하는 방식이 대표적이다. 아니면 데이터 전체를 reconstruction해버리는 generative model들도 self-prediction에 포함된다. 또한 데이터들의 특징에 따라 task를 우리가 정의해볼 수도 있다. 특히 최근에는 일부를 random masking하고 이를 prediction(reconstruction)하는 방식이 가장 많이 사용된다.
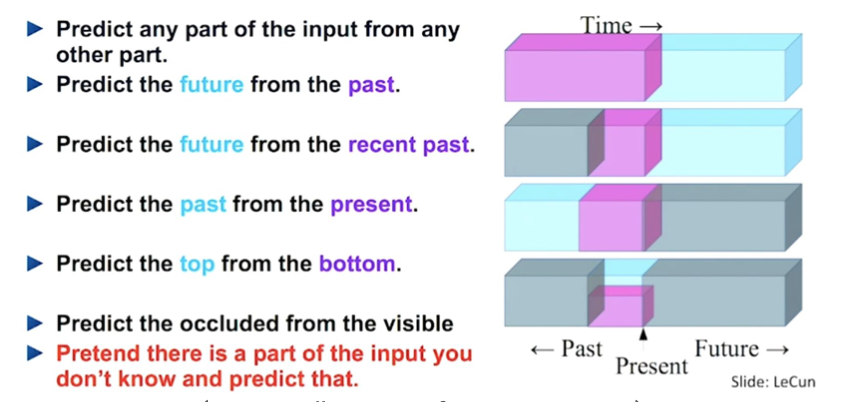
크게 구분하면 아래 4가지 방법으로 나눌 수 있겠다.
- Autoregressive generation
- Masked generation
- Innate relationship prediction
- Hybrid self-prediction
1. Autoregressive generation
Autoregressive 모델의 경우 이전의 behavior를 통해 미래의 behavior를 예측한다. sequential한 방향성(순서)이 있는 데이터라면 regression으로 모델링이 될 수 있다. language처럼 문장을 이어나가면서 다음에 올 단어를 예측하는 경우가 그런 경우다. 관련 모델로는 audio에서는 WaveNet, language에서는 GPT, XLNet, image에서는 PixelCNN등이 있다. 단독으로 쓸 수도 있지만 VQ등의 기법과 함께 사용될 때 더 효과가 좋다.

2. Masked generation/prediction (***)
우리는 정보의 일부를 마스킹하여 마스킹되지 않은 부분을 통해 missing영역을 예측하도록 한다. 이를 통해서 과거정보 뿐 아니라 앞뒤 문맥을 파악하여 relational 정보를 이해할 수 있다. masking된 영역을 generation/prediction하는 task의 경우 random masking으로 masking 범위가 계속 변화하기 때문에 다양한 scale 혹은 size에 대한 학습이 가능하다는 점에서 좋은 성능이 나오지 않나 싶다. 요즘은 masked prediction방식이 contrastive learning보다도 좋은 성능을 내고있기도 하다. 관련 모델로는 language에서는 BERT, image에서는 denoising autoencoder, 요새 핫했던 masked autoencoder (MAE), simMIM 등이, modality-agnostic하게는 Data2Vec(Input의 masking을 prediction 하는게 아니라 latent를 prediction한다는 점에서 차이는 있지만..)등이 있다.




3. Innate relationship prediction
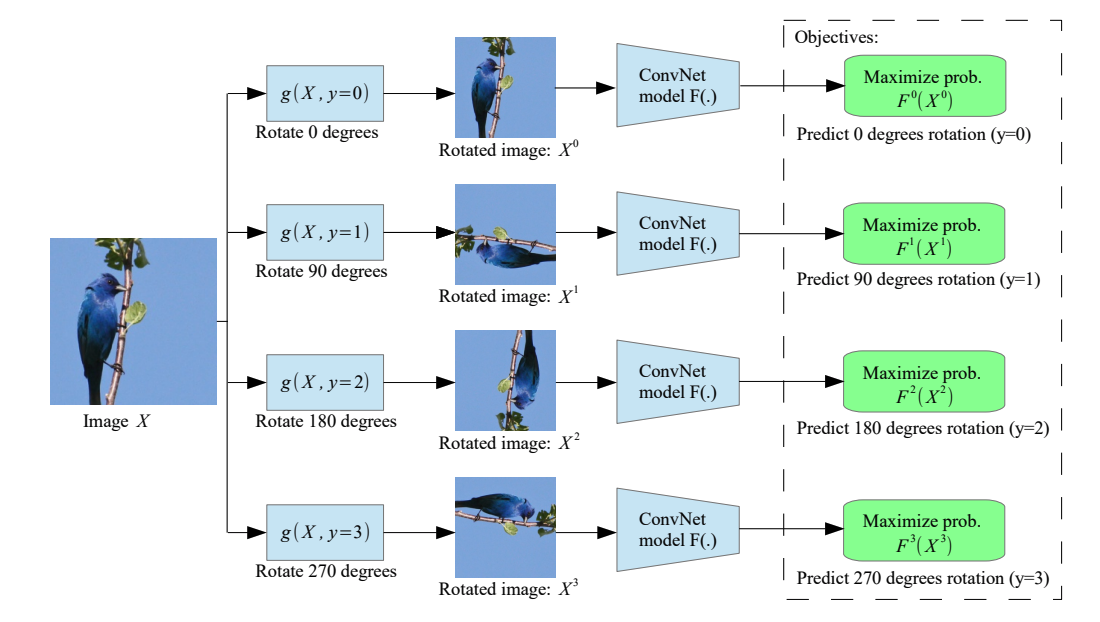
segmentation이나 rotation등의 transformation을 하나의 샘플에 가했을 때도 본질적인 정보는 동일할 것이라는 믿음으로 relationship을 prediction하는 방식이다. domain knowledge가 필요해 대체로 이미지에서 자주 사용된다. 예를 들어 image에서 어떤 rotation이 적용되었는지 예측하거나[3, 4] augmentation 정도를 맞추거나 patch기반의 jigsaw퍼즐을 풀거나 시계열 데이터의 경우 segment shuffle로 순서를 classification하는 등의 방식이 있다. 이러한 task는 만들기 나름이며 간단한 task가 representation 학습에 얼마나 도움이 될까 싶지만 생각보다 아직도 많이 쓰이는 방법이다. augmentation invariant한 feature를 뽑으려는 contrastive learning과 다르게 어떤 augmentation이 어떻게 쓰였는지를 맞추는 task를 쓰게 되면 augmentation aware한 feature를 뽑을 수 있다. 단독으로 쓸 수도 있지만 contrastive learning에 추가하여 보조적인 역할로 쓰기도 한다.
4. Hybrid self-prediction
앞선 여러가지 방식을 짬뽕해서 나오는 hybrid 모델들도 존재한다. 관련 모델들로는 VQ-VAE와 autoregressive방식을 결합한 Jukebox나 DALL-E같은 방식들도 있다. VQ-VAE와 autoregressive, adversarial을 결합한 VQ-GAN도 있다. 대용량 데이터를 활용하기 때문에 실제로 개인이 연구하기 힘든 부분이 있을 수 있으나 눈여겨봐야하는 방법들이다.


Contrastive learning (***)
Contrastive learning의 목적은 "invariance를 학습하는 것이다" (변하지 않는 고유의 성질..일종의 semantic?). 그를 위한 방법으로 embedding space에서 유사한 sample pair들은 거리가 가깝게 그리고 유사하지 않은 sample pair의 거리는 멀게 한다. 용어를 간단히 설명해보면, 유사한지/유사하지 않은지에 기준이 되는 현재 data point를 anchor라고 한다. 그리고 anchor와 유사한 샘플을 positive point라고 하고 anchor와 positive pair를 이룬다. 반대로 anchor와 유사하지 않은 샘플을 negative sample이라고 하고 이는 anchor과 negative pair를 이룬다. 아래에 용어를 정리해두겠다.
- Anchor: 현재 기준이 되는 데이터샘플 (query라고도 함)
- Positive pair: 기준이 되는 데이터샘플과 같은 class를 가지는 상관관계가 높은 데이터샘플 (key라고도 함)
- View: anchor와 같은 semantic을 가지는 데이터샘플 (positive sample). 사물을 보는 다양한 시각이 있듯이 anchor와 동일한 의미를 가지는 다른 샘플들을 생성할 수 있다. anchor 기준으로부터 augmentation을 한 샘플이나 아예 다른 modality가 view가 될수도 있다. (ex) 개를 음성과 이미지로 표현한다면 그 음성과 이미지는 같은 정보를 나타내는 view들이다.)
- Negative pair: 기준이 되는 데이터샘플과 다른 class를 가지는 상관관계가 낮은 데이터샘플

contrastive learning에 대해 아래 4가지로 나눠 설명해보겠다.
- Background and theories
- Inter-sample classification
- Feature clustering
- Non-contrastive methods with joint embedding architecture (new!)
1. Background and theories
Siamese network and representation collapse(or dimensional collapse)
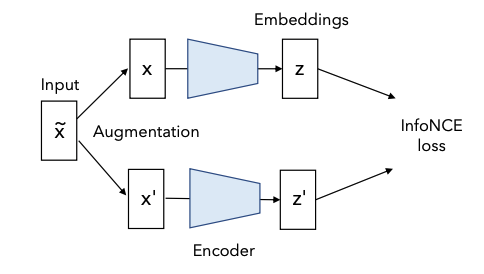
Contrastive learning은 Siamese network를 기반으로 발전했다. Siamese network는 입력으로부터 얻은 두개의 augmented views x1과 x2에 대한 latent를 matching시키는 방식으로 작동하는 unsupervised learning방법이다. 해당 방법은 different view간의 correlation을 maximize하거나 distance를 minimize하는 방식으로 작동한다.(= contrastive learning에서 positive pair간 가까워지는 부분에 해당) 이러한 학습방식의 의미는 하나의 사물에 대해 다양한 관점(view)으로 보며 다양한 관점들의 공통의 정보를 추출해내겠다는 것이다. 예를 들면 고양이 이미지에 노이즈를 추가한 augmented 이미지와 원본 이미지 사이의 공통된 정보는 고양이 객체부분이므로 이부분 (=identity revealing part / semantic part)을 학습하게 될 것이다. 그 외의 배경이나 노이즈는 무시하고 중요한 정보만 학습하게 되는 것이다.


하지만 distance loss로 학습하게 되면 생기는 문제가 모델의 출력이 constant가 되어도 loss가 작아질 수 있다는 것이다. 그래서 representation이 잘 학습되지 않는 representation collapse현상이 발생한다. 이러한 단점을 극복하기 위해 negative sample이 등장하는 contrastive learning방법들이 등장하게 된다. (large batch size를 요구하는 단점도 있음, contrastive learning 또한 dimensional collapse를 완전히 해결하진 못함)

Contrastive learning captures shared information between views
앞서 설명한 Siamese network의 공통 정보의 추출이라는 의미는 contrastive learning의 대표적인 loss식인 InfoNCE를 제안한 논문에서 이론적인 증명이 되었다. (= contrastive learning을 쓰면 shared information이 추출된다!) 해당 논문에서 infoNCE loss는 view들 사이의 mutual information의 lower bound가 됨을 증명했다.
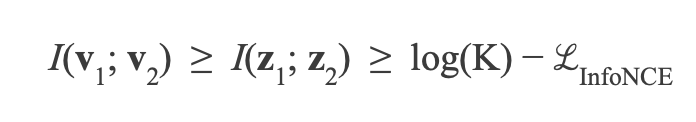
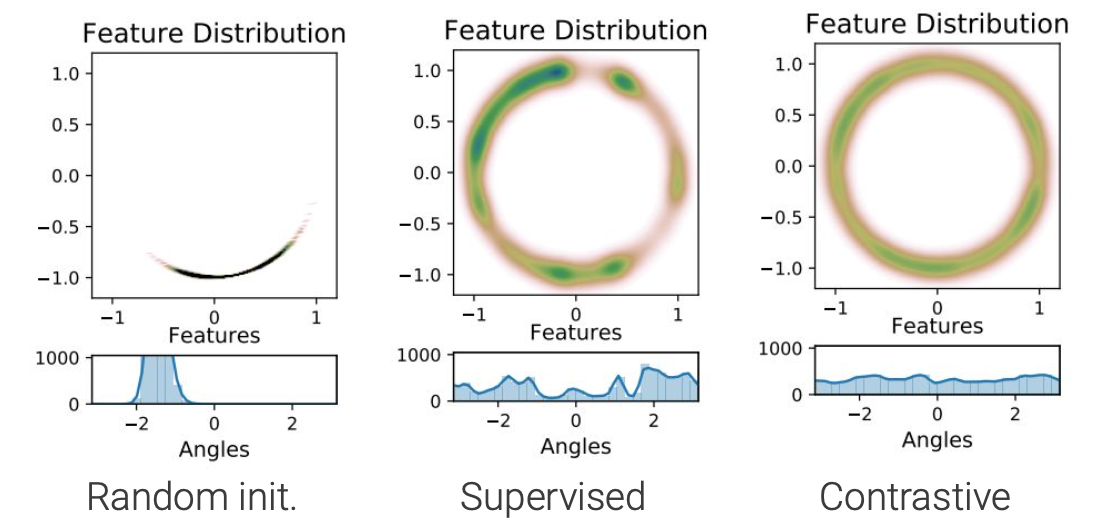
Alignment and Uniformity on the Hypersphere
Contrastive하게 학습된 feature들은 supervised learning을 통해 학습한 feature보다 훨씬 uniform하고 aligned되었다는 것도 실험적으로 증명이 된 바 있다. 같은 class인 샘플들이 가까운 위치에 있어야하는 alignment도 중요하고 그러면서도 각각의 instance가 고유의 특성을 유지하기 위해 uniformity도 중요한데 InfoNCE등의 loss를 통해 이러한 부분이 어느정도 충족된다는 뜻이다. 직관적으로 생각하면 positive pair간 가까워지는 것이 alignment에 기여한다고 볼 수 있다. 그리고 negative pair간 멀어지는 것이 uniformity를 만족하는데 기여한다고 볼 수 있다. (-> negative pair에는 같은 class의 샘플들도 존재, 같은 class의 샘플들 사이에서도 서로 다른 특징이 존재하는데 이를 살려주는 것을 의미)
- Uniform: feature가 hypersphere에서 uniform하게 distribute되어야 한다.
- Aligned: 같은 입력으로부터 온 두개의 view는 같아야 한다.
2. Inter-sample classification (=Instance discrimination)
contrastive learning의 등장배경과 contrastive learning의 이론들을 통해 왜 contrastive learning이 성능이 좋은지에 대해 알아봤다. 이제 contrastive learning을 어떻게 하는지에 대해 설명하도록 하겠다. contrastive learning은 instance를 구별하는 일종의 classification task를 pretext task로 삼는 방법으로 볼 수 있는다. simliar ("positive")와 dissimilar ("negative") 후보들이 주어질 때, anchor data point와 simliar한게 무엇인지를 구별하는 것이기 때문이다. 이러한 방식의 대표 논문은 MoCo, SimCLR이 있다. different view로 생성한 positive pair (x1, x2)는 각각 다른 encoder를 통과하고 서로 가까워지도록 학습한다. 그리고 다른 class를 가지는 negative sample은 서로 멀어지도록 학습한다.
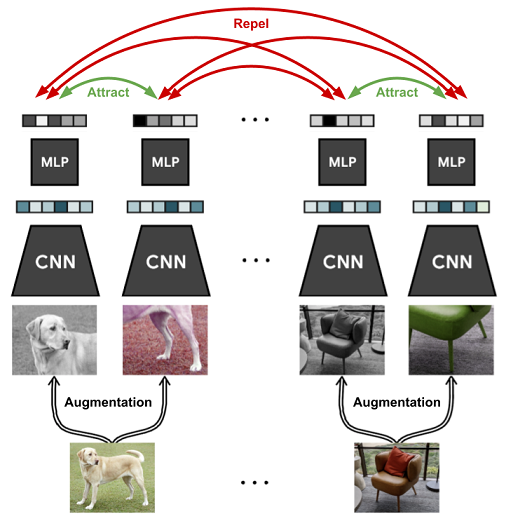
Contrastive learning에서는 positive sample과 negative sample을 어떻게 선정하는지가 성능에 크게 영향을 미친다.
positive pair를 고르는 방법 중 하나는 augmentated view(image의 경우 다양한 aumentation기법들이 존재한다)를 통해 원본의 distorted version을 만드는 것이다. 다른 방식으로는 하나의 데이터에 대한 different view를 positive pair로 선정할 수 있다. 예를 들면, RGB각 채널 중 한채널씩만 가져간다던지 identity는 유지하고 아예 다른 modality도 하나의 view가 될 수 있다. 또한 최근에는 이미지 외의 domain에서 유의미한 augmentation을 찾기 힘들어 neural transformation으로 positive view를 생성하기도 한다.
그럼 반대로 negative pair는 어떻게 선정할까? label이 있다면 label정보를 활용할 수 있다. 하지만 우리는 unsupervised setting이기 때문에 매우 심플하게 SimCLR에서는 batch내에 anchor 아닌 다른 샘플들을 negative sample로 본다. (batch내에 anchor와 positive인 샘플이 있다면 오히려 학습에 방해가 되기 때문에 이를 해결하기 위한 연구도 존재함 [1]) 다양한 연구들을 통해 negative sample은 갯수가 많을수록 representation collapse를 방지하는데 효과가 좋다고 알려져있다. 그래서 batch size를 크게하거나 MoCo처럼 negative sample을 queue에 쌓아서 샘플 수를 늘리는 방식을 사용하기도 한다.
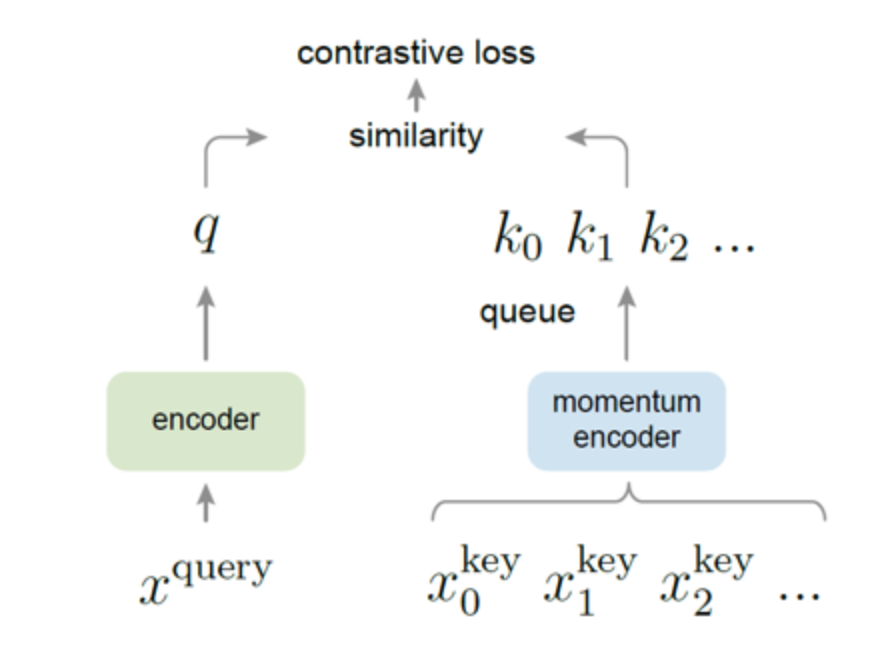
그럼 positive pair끼리 가까워지고 negative sample끼리 멀어지는 것은 어떤 objective function으로 학습되는 걸까? Inter-sample classification을 위한 loss들은 다양하게 있는데 그 중 유명한 몇가지 loss를 소개하겠다. (*대체로 constrastive loss는 distance와 similarity를 기반으로 한다.)
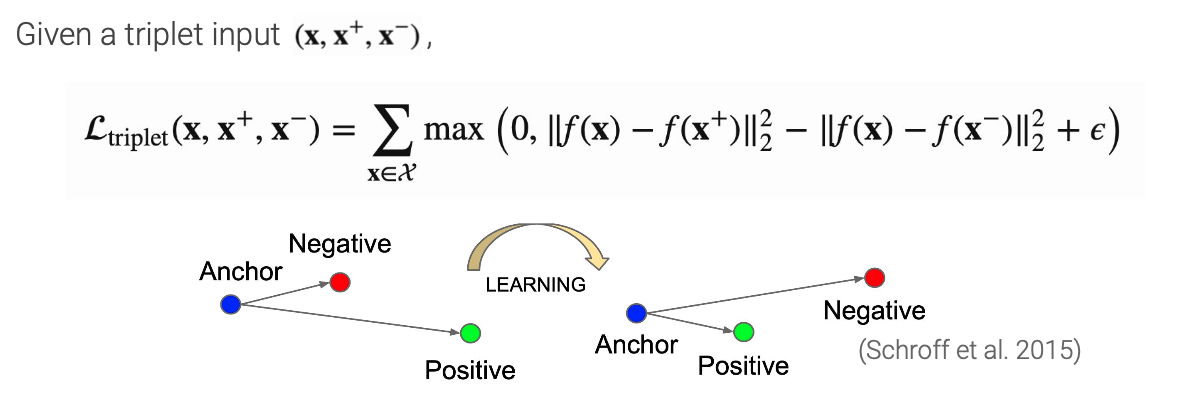
Triplet loss
Triplet loss는 distance를 기반하는 loss로 metric learning의 일종으로 볼 수 있다. embedding space에서 sample들 사이의 유사도를 distance로 판단한다. anchor와 positive 사이의 distance는 minimize하는 동시에 negative와의 distance는 maximize하는 간단한 방식이지만 지금까지도 꽤나 잘 사용되는 방식이다.
InfoNCE
NCE에서의 noise를 multiple로 확장한 loss로 볼 수 있다. contrastive learning의 근본으로 볼 수 있는 CPC (Contrastive Predictive Coding) 논문에서 이름을 붙인 loss로 target data를 관계가 없는 noise samples(negative samples)와 구분하기 위해 categorical cross-entropy loss를 사용한다. cross-entropy로 결국 정리가 되지만 내부적으로 positive sample의 context vector와 input vector의 mutual information을 크게 가져가는 효과가 있다. (InfoNCE는 view들간의 mutual information의 lower bound이므로 이를 minimize하는 것은 view들 사이의 mutual information을 maximize하는 것)


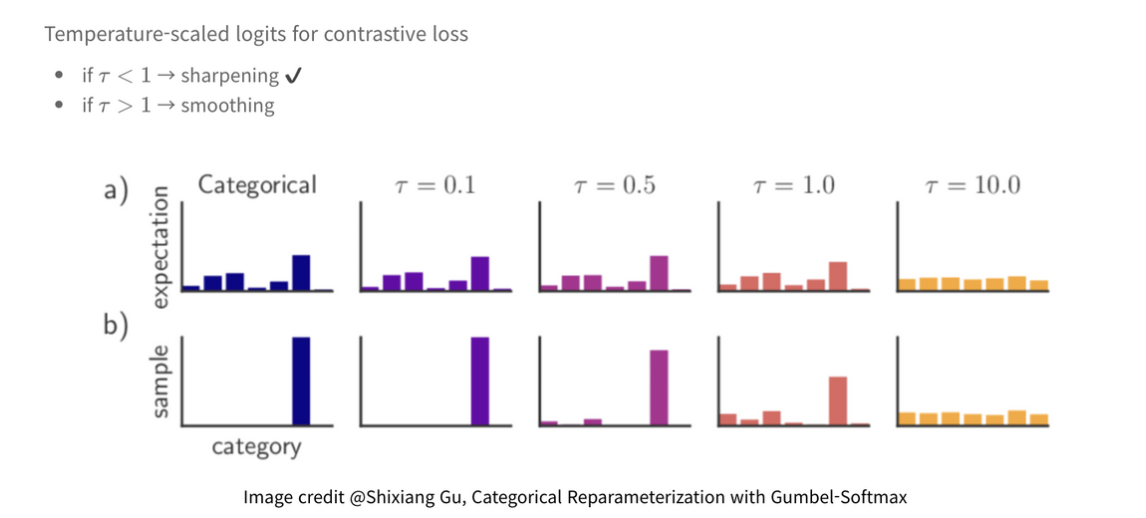
아래의 형태가 더 익숙할 것이다. positive pair간의 dot product(similarity)는 크게, negative pair간의 dot product는 작게하는 형태를 가진다. 요즘 나오는 contrastive learning은 아래의 loss를 거의 사용하니 얘는 꼭 알아두자. (구현이 사실 신박하고 간단한데 관련해서는 해당 블로그에 자세히 정리되어있다.)


3. Feature clustering
feature clustering method는 positive pair 생성으로 instance를 discrimination하는 것이 아니라 encoder를 통해 학습된 feature representation으로 데이터 샘플들을 clustering함으로써 만들어진 class들에 pseudo-label을 명시적으로 달고 이를 토대로 inter-sample classification을 진행하는 방식이다. (cluster의 center를 prototype으로 부르기도 한다.) Feature clustering방식은 batch내의 anchor이외의 나머지 샘플들을 모두 negative sample로 보는 문제에 대한 대안으로 볼 수도 있을 것 같다. 관련 모델로는 DeepCluster, SwAV, InterCLR등이 존재한다.


4. Non-contrastive methods with joint embedding architecture (***)
Contrastive learning의 가장 큰 단점은 representation collapse를 해결하기 위해 많은 negative sample이 필요하다는 것이다. 그래서 negative pair가 없이도 representation collapse 문제를 극복할 수 있는 다양한 방식들이 연구되고 있다.
BYOL & SimSiam
BYOL은 teacher-student구조를 가지며 momentum encoder의 경우 encoder의 파라미터를 Exponential Moving Average(EMA)를 통해 앙상블하는 형태가 되어 안정적인 representation이 학습 가능하게 했다. SimSiam은 더 나아가 momentum encoder를 사용하지 않고 stop-gradient를 활용하여 representation collapse를 막았다. 두 모델 모두 predictor를 활용한다. 기본적으로 모델의 후반 layer로 갈수록 task specifc한 정보가 모이게 되는데 이를 predictor로 빼면서 encoder에는 더 순수한 representation이 형성되게 된다.

Barlow Twins & VICReg
Barlow Twins와 VICReg는 기본적으로 representation dimension안에서의 disentangle개념이 들어있다. latent를 추출할 때 각 dimension이 다른 의미를 가지면 더 제대로 된 representation이 학습되고 collapse가 해결될 것이라는 생각이 들어있는 듯 하다. Barlow Twins의 경우 positive pair간의 cross correlation matrix를 구해서 이 matrix가 identity matrix가 되도록 loss를 준다.
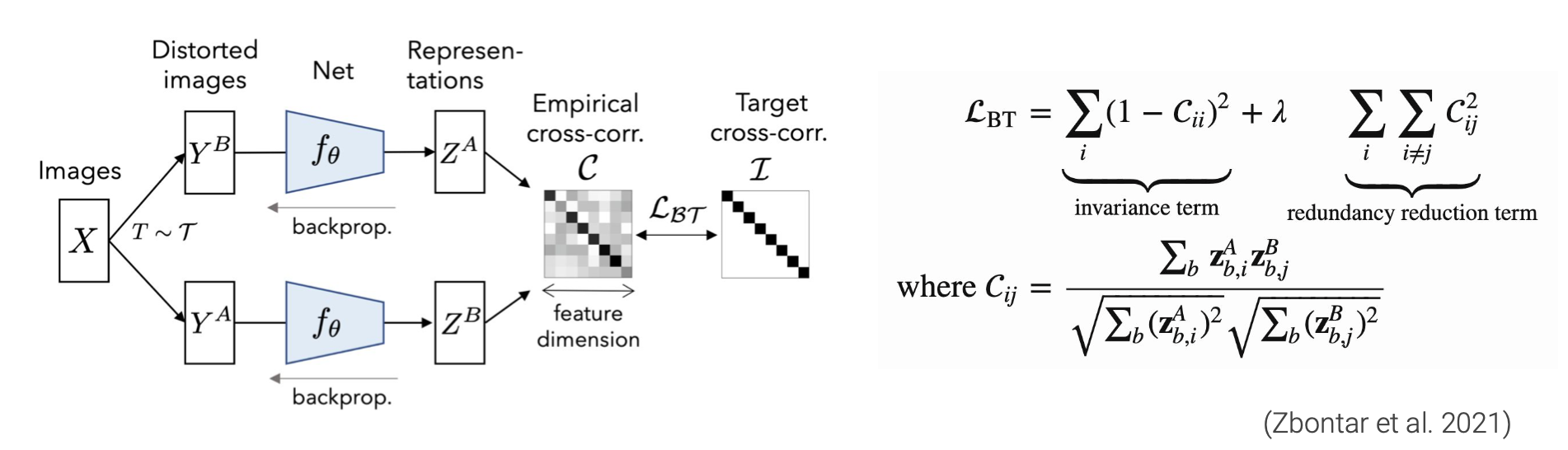
VICReg는 더 나아가서 batch내 샘플들의 representation의 variance를 고려한다. 직접적으로 representation의 variance가 0이 되지 못하도록 하여 representation collapse를 막는 regularization term을 주는 것이다.

DINO [5]
DINO는 앞선 BYOL이나 SimSiam처럼 Teacher-Student구조를 가지고 있지만 다른 점은 representation collapse를 방지하기 위해 단순히 centering과 softmax layer에서의 sharpening을 활용한다. centering의 경우에는 전체 feature를 center로 조정해주는 역할을 한다. 이럴 경우 하나의 dimension이 우세해지는 것을 막아줄 수 있다. 하지만 uniform distribution으로 collapse할 수 있다. 이를 방지하기 위해 sharpening을 적절하게 섞어주는데 softmax probability계산시 temperature term을 조절해주는 것이다. 이를 통해 centering과 반대의 효과를 준다. 이 두 기법이 잘 조화를 이루면 representation collapse가 간단히 방지된다고 한다.


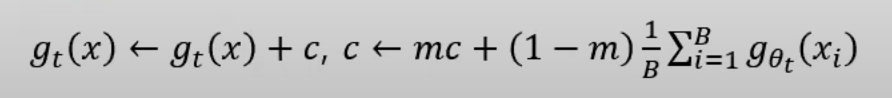
I-JEPA [6]
앞선 타 방법들과 다르게 JEPA는 hand-craft augmentation이 필요없는 Joint embedding "predictive" architecture를 제안한다. pedictive라는 말은 dino같은 방식과 다르게 joint embedding을 하되 contrastive 방식이 아닌 reconstruction 방식을 취하는 것을 뜻한다. JEPA는 맞춰야하는 target embedding을 만드는 target encoder와 target을 맞추기 위해 필요한 정보인 context embedding을 만드는 context encoder 두개의 encoder를 가진다. 학습은 context emebdding을 활용해 target embedding을 맞추는 latent reconstruction을 하는 단순한 방식이다. 앞선 discrimination방식에 비해 local한 segmentation task에서 좋은 성능을 보였고 또한 view-invariant한 task에서도 유사하거나 조금 더 좋은 성능을 보였다.

Masked prediction vs Contrastive learning
Contrastive learning이 굉장히 각광받았지만 현재는 self-prediction계열의 masked prediction 모델들이 fine-tuning성능이 더 높다는 결과들이 많이 나오고 있다. 하지만 실제로는 task마다 데이터셋 사이즈마다 성능 우위가 다른 상황이다. 그를 통해 두 방법이 서로 다른 representation을 배우고 있다는 것을 알 수 있다. 학습방식에서 유추할 수 있듯이 masked prediction은 token을 복원하는 방식으로 local한 level의 정보(texture/high frequency representation)를 학습하고 있고 contrastive learning은 샘플 전체에 대한 view간의 agreement를 학습하기 때문에 global한 level의 정보(shape/low frequency representation)를 학습함을 알 수 있다. 실험적으로 여러 논문에서 각 방식의 representation이 어떻게 형성이 되는지 실험적으로 보여주고 있으니 관련 내용을 참고하면 재미있을 것이다. [2]
Future direction
- 큰 batch size는 transfer성능을 향상시킬 것이다.
- 높은 퀄리티의 large data corpus는 더 좋은 성능을 낼 것이다. (데이터 싸움)
- 효과적인 negative sampling방식에 대한 고민이 필요할 것이다.
- 다양한 pretext task를 combine하는 방법에 대한 고민 -> 어떻게? 가장 좋은 방법은?
- 현재 data augmentation trick들은 모델에 critical한데 여전히 ad-hoc하다. -> 이론적 토대 필요, modality-agnostic필요
- 학습의 효율성 측면에서도 개선해야할 부분들이 많다. (경제적, 환경적 비용감소 측면)
- embedding space에서의 bias를 제거해야한다.
Reference
[1]: https://arxiv.org/pdf/2011.11765.pdf
[2]: https://openreview.net/pdf?id=azCKuYyS74
[3]: https://arxiv.org/pdf/1805.10917.pdf
[4]: https://proceedings.neurips.cc/paper/2020/file/8965f76632d7672e7d3cf29c87ecaa0c-Paper.pdf
'Review > Reading' 카테고리의 다른 글
| Unsupervised Anomaly Detection for Tabular Data Using Noise Evaluation 논문 리뷰 (0) | 2025.03.14 |
|---|---|
| Deep Weakly-supervised Anomaly Detection 논문 리뷰 (0) | 2025.03.04 |
| DRL: DECOMPOSED REPRESENTATION LEARNING FOR TABULAR ANOMALY DETECTION 논문 리뷰 (2) | 2025.02.10 |
| Semi-supervised learning (준지도학습): 개념과 방법론 톺아보기 (6) | 2021.09.09 |
| Glow: Generative Flow with Invertible 1X1 convolutions 논문 리뷰 (2) | 2020.06.14 |



