Speech Chain
speech coding이나 speech recogntion등의 speech를 처리하는 실질적인 시스템을 만들기 위해서는 실제로 인간이 어떻게 speech를 통해 서로 communication하는지 아는 것은 매우 중요하다. 결국 우리는 인간이 하는 음성의 인식과정을 기계가 모사하도록 만들고싶기 때문이다. 우리가 말하고 그 말을 듣고 이해하는 과정을 알아보도록 하자.
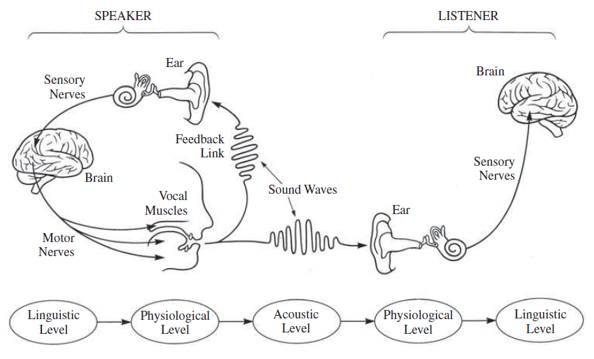
음성이 생성되어 전달되는 과정을 네트워크의 5계층처럼 단계별로 나누어 표현할 수 있겠다.
- Linguistic level: 어떤 생각이나 아이디어를 표현하기 위해서 어떤 sound로 말을 할지 basic sound를 선택하는 레벨
- Physiological level : vocal tract의 구성요소들이 언어학적 발화단위와 연관해서 소리를 만드는 레벨
- Acoustic level : 실제로 소리가 입과 코를 통해 나오고 스피커와 리스너 모두에게 전달되는 레벨
- Physiological level: 소리가 귀와 청각신경에서 분석되는 레벨
- Linguistic level: 음성이 인지되고 언어학적인 단위의 열로 하나의 의미로 인지되는 레벨
음성으로 두 사람이 communication을 한다면 한사람은 음성을 생성해야겠고 한명은 음성을 들어야된다. 그러므로 그걸 두 가지 시스템, 소리를 생성하는 시스템 / 소리를 듣는 시스템 으로 나누어 각각 설명하도록 한다.
Speech production system: 소리를 생성하는 시스템
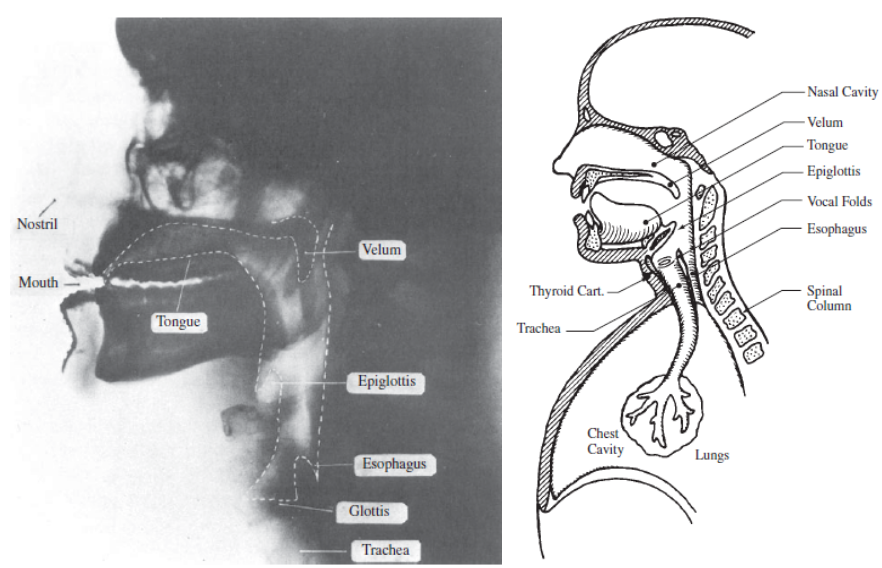
소리를 생성해내는 기관들을 표시한 그림이다. 이 소리는 조음기관이 어떻게 위치되었느냐에 따라 vocal cord(성대)에 가해지는 압력이 달라지면서 다른 소리가 나게 된다.
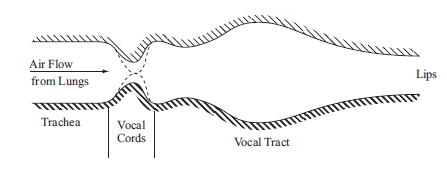
폐에서 부터 공기의 흐름이 생기고 그게 vocal cord(성대)를 울리게 된다. 성대가 울리게 되면 준주기적인 pulse가 발생하여 유성음을 만들게 되고, 성대가 울리지 않으면 noise-like한 신호가 발생하여 무성음을 만들게 된다. 또한, 그렇게 생성된 excitation신호는 vocal tract(성도)의 모양에 따라 (모델링한다면, 여러 파라미터로 모델링) 다른 공명(resonance)주파수를 갖게되어 서로 다른 소리가 만들어진다. 그러므로 내가 어떤 단어를 말해야겠다고 생각한다면, 그단어를 표현하는 소리를 선택하고 조음기관을 그 소리에 맞게 조율한 후 소리로 만들어내는 것이다.
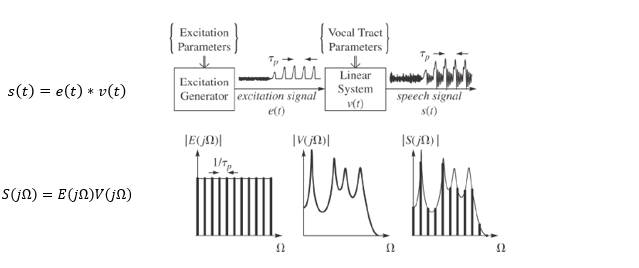
이를 시스템으로 구현해보면 위와 같다. 음성신호라는 것은 유성음/무성음의 excitation신호에(유성음일 경우 주기에 해당하는 pitch period를 갖는다) vocal tract시스템을 통과해 각기 다른 formant주파수를 갖는 신호를 생성해내는 것이다. 그래서 s(t)는 excitation신호를 vocal tract시스템에 통과시킨 것이므로 컨벌루션 연산으로 나타낼 수 있다. 그리고 주파수상에서도 표현할 수 있겠다. 주파수상에 표현한 그림은 유성음일 때로, pitch마다 신호가 발생하는 것을 확인할 수 있다. 이렇게 생성된 각각의 소리단위들(음소, Phoneme)은 모두 다른 특성의 스펙트로그램을 생성한다.
Auditory system: 소리를 인지하는 시스템
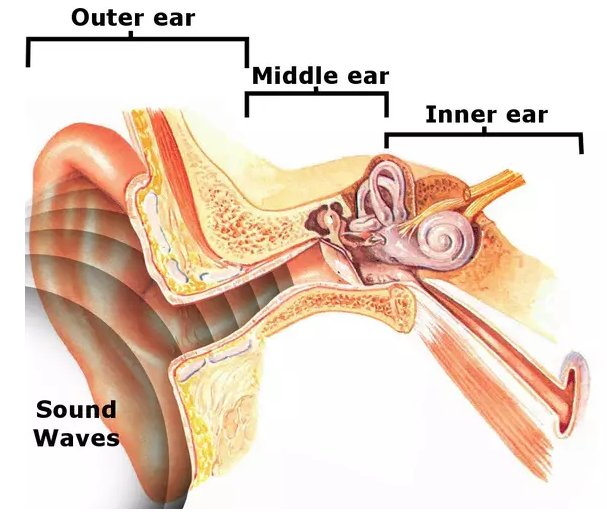
외이,중이,내이로 귀의 각 부분의 기능을 이해하면 인간의 듣는 과정을 이해할 수 있다. 인간의 auditory system을 나타내는 그림을 통해 듣는 원리를 이해해보자. 일단 외이는 귓바퀴와 소리가 이동하는 통로인 외이도를 포함하고있다. 귓바퀴는 클수록 저주파성분을 잘 듣는 경향이 있다. 소리의 에너지는 거리의제곱과 반비례하기 때문에, 음원의 거리가 멀수록 더 퍼지는 경향이 있다. 그렇게 귓바퀴로 들어온 소리는 외이도를 타고 중이로 전달되게 된다. 중이는 고막, 그리고 서로 연결되어있는 작은 뼈들(추골,침골,등골)로 이루어져있다.
중이의 기능은 sound wave(acoustic signal)을 고막에서 mechanical한 vibration으로 바꾸는 것이다. 세개의 뼈인 추골,침골,등골은 소리의 진동을 증폭시키는 역할을 하고, 이 세개의 뼈를 감싸는 근육은 지나치게 큰 소리를 감쇄시키는 역할을 한다.
이제 소리는 진동으로 바뀌었다. 그리고 이 진동은 내이로 전달된다. 내이에는 달팽이관이 존재한다. 달팽이관은 몸에서 마이크의 역할을 하게 되는데, Sound pressure signal을 전기적인 impulse로 변환한다. 이때 변환된 전기적 impulse가 청각신경을 통해 뇌에서 인지되게 된다. 우리가 설계하는 Deep learning system은 이를 처리하는 뇌부분을 맡게 될 것이다. 내이에서의 작용을 더 자세히 살펴볼 필요가 있다.
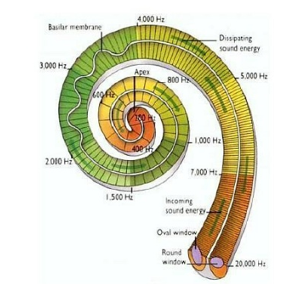
달팽이관은 두바퀴 반 말려있고 약 3cm의 길이를 가진다. mechanical한 떨림이 달팽이관으로 들어오면 기저막을 진동시킬 정상파를 만들어낸다. 달팽이관에는 기저막이라는 막이 존재하는데 이는 달팽이관을 두개의 튜브로 나누는 막이다. 위의 그림에서 달팽이관 내부에 중간에 있는 하얀색 막이 기저막이다. 기저막은 위치에 따라 두께나 뻣뻣한정도가 다르다. 왜냐면 그 요인들에 의해서 기저막이 '소리의 진동'에 가장 민감해지는 '주파수값'이 달라지기 때문이다.
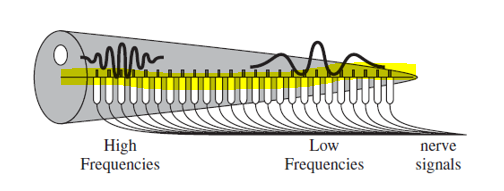
기저막의 위치에 따라 특정 주파수에 민감하게 반응하는 모습을 보여주는 그림이다. 그래서 소리가 높은 주파수에서 낮은 주파수까지 spectral하게 분석되는 것이다. 기저막은 3000개보다 더 많은 sensor에 의해 연결되어 있는데, 이 sensor를 inner hair cell이라고 한다. 기저막의 진동은 본질적으로 인간이 귀를 통해 들을 수 있게 하는 것이다. 기저막이 움직일때, 이 inner hair cell이 다른 주파수에 의해 튜닝되고 다른 비율로 진동하게 된다. 기저막의 진동이 충분히 크면 inner hair cell의 진동이 뇌에 전기적 impulse를 발생시킨다. 각각의 inner hair cell은 대략 열개의 신경섬유와 연결되어있고, 각각은 다른 지름을 가진다. 높은 모션레벨에서는 얇은섬유, 낮은 모션레벨에서는 두꺼운 섬유를 갖는다. 그래서 이런 전기적 impulse는 신경섬유를 통해 인간의 뇌에 도달해서 decode되는 것이다.
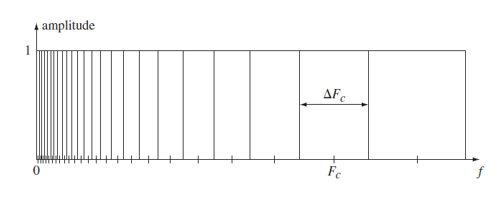
기저막은 기저막의 각각 다른부분에서의 주파수응답set을 가진다는 특징이 있다. 우리는 저주파에서 더 세심하게, 고주파에서 더 rough하게 소리를 인지한다. 이를 시스템으로 구현해보려면 non-uniform한 필터뱅크라고 할 수 있다. 높은 주파수부터 낮은 주파수까지 logarithmically한 경향이 있다. 이를 위의 필터뱅크그림으로 설명할 수 있다. 이런 과정을 통해서 이렇게 인지된 소리를 들리는 대로 인지하는 것이 음성인식이 될 것이고 이해하는 것이 자연어처리의 일이 되겠다.
Reference
Lawrence R. Rabiner “Theory and Applications of Digital Speech Processing”
https://www.scienceabc.com/humans/basilar-membrane-what-is-it-and-what-does-it-do.html
'Domain Knowledge > Speech' 카테고리의 다른 글
| LPC(Linear Prediction Coding, 선형예측부호화)와 formant estimation (0) | 2020.07.31 |
|---|---|
| Pitch detction(ACF, AMDF, Cepstrum) (0) | 2020.07.31 |
| 음성신호처리에서 frame 생성시 overlap을 하는 이유 (5) | 2020.07.30 |
| STFT(Short-Time Fourier Transform)와 Spectrogram의 python구현과 의미 (6) | 2020.07.30 |
| DFT(Discrete Fourier Transform)와 Circular Convolution (3) | 2020.07.07 |



