LPC에 대한 소개
음성신호처리에서 강력한 음성분석기법중 하나가 바로바로 Linear predictive analysis이다. 이 기법은 음성의 생성모델의 파라미터 (그 중 vocal tract 필터)를 예측하는 좋은 방법이다.(이에 대해 아래에 자세히 설명예정) 이 기법은 여러분야에 쓰일 수 있는데 첫째로 낮은 bit rate로 전송(통신)을 하기위한 신호의 한가지 표현으로 쓰일 수도 있고. 압축하여 저장하는데에 쓰일 수도 있다. 또한 automatic speech나 화자인식에 쓰일 수있다.
이번 포스팅에서는 실제적인 음성application에 널리 쓰이는 Linear predictive analysis에 대해 소개할 것이다. Linear prediction방법은 LPC 즉, speech를 coding하는 방식에 제일 먼저 쓰였는데 이 방법이 너무 유명해져서 앞으로 LPC라고 말하면 Linear predictive coding이란 말이지만 coding에 한정되는게 아니라 Linear prediction의 general한 표현이 된다. 그래서 Linear predictive analysis를 그냥 LPC라고 봐도 무방하다.
Linear prediction을 한국어로 번역해보면 선형예측이라는 뜻이다. 예측(prediction)은 이전에 관측되었던 샘플들을 토대로 다음 샘플을 예측하는 것이다. 선형예측(Linear)는 이전 샘플들로 부터 선형모델(linear regression)에 의해 다음 샘플값을 계산하겠다는 말이다. 기본적인 가정은 현재의 샘플이 이전샘플들의 근사적인 선형결합으로 표현 가능하다는 것이다. 현재 음성 표본값을 과거의 표본값들로부터 예측하고, 과거의 표본과의 차이만을 부호화하는 방법을 통해 압축이나 전송에 이용할 수 있는 것이다.
LPC는 인간의 발성모델을 근거로 두고 있다.

음성신호가 생성되는 원리를 단계별로 표현한 그림이다. 우리가 얻는 샘플링된 신호 s[n]은 사실 유성음이냐/무성음이냐에 따라 유성음일 경우 성대의 진동(pitch)를 주기로 excitied되고 성도(vocal tract)의 반응에 따라 여러 소리를 구성해내는 원리로 소리를 낸다. 무성음일 경우 pitch가 존재하지 않고 그냥 랜덤한 excitation이 성도(vocal tract)의 반응에 따라 여러 소리를 만들어낸다. 이때, 성도의 반응을 시간에 따라 변하는 시스템(=필터)로 보고 이의 필터계수를 음성의 특징을 결정짓는 수치벡터로 볼 것이다.
그래서 이 과정을 'excitation된 신호가 어떤 시간에 따라 변하는 시스템(필터)을 통과하면 우리가 듣는 음성 s[n]이 된다' 라고 설명할 수도 있겠다.
우리가 만약 이런 성도(vocal tract)를 필터로 본다면 필터계수를 구할 수 있을 것이다. 이는 곧 음성의 특징을 결정짓는 수치벡터로 볼 수 있겠다. 그러므로, 이산시스템은 차분방정식의 형태로 나타낼 수 있고 이의 계수들을 알아내는 것은 성도(vocal tract)의 특징을 알 수 있는 성도(Vocal tract)시스템의 필터계수 (= parameter)를 추출해내는 과정이 된다.
Vocal tract modeling(All-pole model)과 cost function의 정의
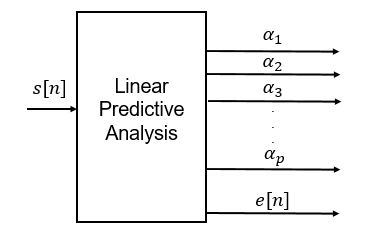
LPA를 하나의 Black box로 보면 이렇게 음성신호의 한 segment를 넣었을 때, vocal tract의 필터계수 + error signal이 나온다. 이 블랙박스에 대해 자세히 알아보자.
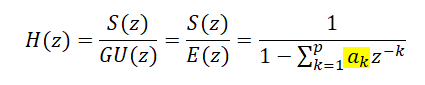
(+선형결합이 어떻게 all-pole model이 되는지 간략히 fourier transform으로 정리해보았다. (notation이 계속 바뀌어 헷갈릴 수 있지만....느낌파악용))

아까 봤던 음성생성모델 그림을 z transform식으로 나타내면 위와 같이 나타낼 수 있다. 우리가 알고싶은 것은 vocal tract의 필터계수이기 때문에 이를 표현하는 H(Z)에 관해 식을 정리할 수 있다. 우리는 vocal tract를 all-pole modeling할 것이기 때문에 분모 term만 존재하는 것을 확인할 수 있다. 여기서 우리가 풀어야하는 가장 기본적인 문제는 predictor coefficient가 되는 ak(k=1,2......p)를 구하는 것이다. 그러나 음성신호는 시간에 따라 신호의 특성이 바뀌는 time-varying한 속성을 가지고 있다. 그러므로 분석은 짧은시간안에서는 신호의 특성이 변화하지 않는다는 가정을 가지고 short-time으로 분석을 해야한다. 또한 이 과정은 Mean square error를 최소화하는 (linear regression) parameter를 찾는 방식으로 진행된다.

원 신호 s[n]은 p개의 이전 샘플들의 선형결합으로 추정할 수 있다. 하지만 이 추정도 에러가 존재할 수 있기 때문에, 뒤에 predictive error signal e[n]을 더해서 표현할 수 있다. 여기서, error는 excitation signal에 gain을 곱한 값으로 표현될 수 있다.
**excitation신호
1.유성음일 경우, pitch period(주기적으로 울리기 때문)마다 impulse가 뜨는 신호
2.무성음일 경우, noise-like한 신호
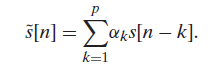
p차 linear predictor는 위와 같이 정의할 수 있다.

원 신호와 추정신호의 z-변환 해서 system function을 구한 것을 P(z)라고 정의하자. 그리고 이를 predictor polynomial 이라 부르겠다.

Predictive error signal은 아까도 말했듯이 원래 신호에 추정신호를 뺀 값으로 정의할 수 있다.
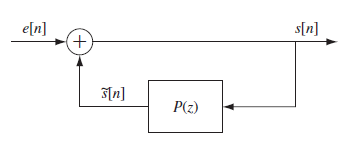
이를 diagram으로 나타내면 다음과 같다. 굳이 diagram을 설명해보자면, 우리가 들을 수 있는 s[n]을 이용해서 s[n]과 유사해지도록 P(z)의 파라미터들을 조금씩 바꿔본다. 파라미터를 바꿔서 추정한 s[n] 을 원래 s[n]과의 차이가 작아지도록 계속 파라미터를 수정하는 과정이 된다.

P(z)를 이용해서 A(z)라는 것을 새로 정의 할 수 있다. 1-P(z)를 A(z)라고 하면 에러를 원래 signal을 넣으면 error가 나오는 system function을 정의할 수 있다. 그래서 이를 prediction error filter라고 한다.(=LPC polynomial)
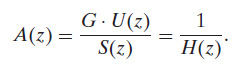
Error를 excitation으로 근사하였기 때문에 위와같이 나타낼 수 있고, H(z)는 처음에 음성모델을 토대로 정의한 바 있으므로 A(z)는 H(z)의 역수로 볼 수 있다.
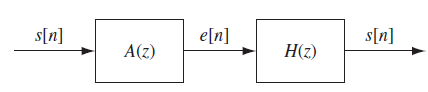
그러므로 이를 diagram으로 정리해보면, 음성신호가 prediction error filter(A(z))를 통과하면 error signal(excitation이라고 추정되는 놈)이 나온다. error signal이 vocal tract system(H(z))를 통과하면 음성신호가 나온다. 둘은 inverse system관계이다.
이 모델의 장점은 'gain G와 filter계수 ak가 LPA로 바로 예측될 수 있다는 것' 이라고 한다. vocal tract(성도)를 all-pole model로 식을 세우고 LP coefficient만 찾으면 되기 때문. (대신 이 모델자체가 잘 모델링된게 아닐 수 있기 때문에, LP파라미터를 찾아도 산으로 갈 수 있다는 단점이..) 앞서 추정한 speech와 원래 speech사이의 차의 제곱으로 error function을 정할 수 있다. 그리고 이를 최소화 하는 a를 찾으면 되겠다.
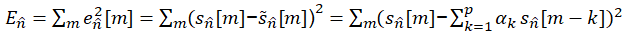
우리는 총 에러를 각각의 ak에 대해 편미분을 한 것이 0이라고 둔다면 그때가 error가 최소가 되는 시점일 것이다.
LP parameter 구하기: Autocorrelation method(자기상관함수 방식)

여기서 sn[m]은 아래를 만족한다.

앞서 정의한 total squared error를 최소화 하려면 미분해서 0인 지점을 찾으면 된다.
미분해서 정리하면 아래와 같이 나온다.

이를 correlation으로 정리하고 matrix formulation으로 표현하면 아래와 같다.


간단하게 autocorrelataion을 구해서 inverse matrix를 이용해 LP parameter a를 구할 수 있다. 여기서 inverse가 존재하지 않으면 어떻게하지? 하는 생각은 안해도 되는데, autocorrelation은 time-delay가 0일 때, 가장 큰 값을 가지는데 대각성분이 가장 큰 matrix는 항상 inverse를 가진다. 그리고 autocorrelation은 대칭함수이기 때문에 이를 이용해서 더 간단한 계산으로 a를 구할 수 있는데, 유명한 방식으로는 Levinson-Durvin Algorithm으로 a를 구할 수 있다. 요즘은 그냥 inverse해서 구해도 될만큼 컴퓨팅 파워가 좋긴하다.
LPC를 이용한 formant estimation
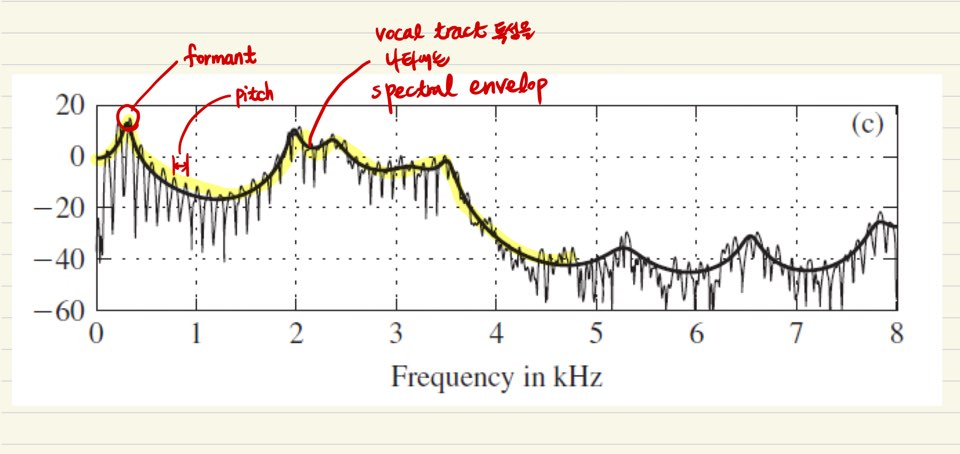
LPC계수를 구한 후 이를 앞선 linear combination식에 대입해 역수를 취하여 DFT를 수행하면, 아래와 같이 원신호보다 smoothing된 spectrum을 얻을 수 있다. 노란선이 LPC를 통해 구한 smoothing된 spectrum이고 이 그래프의 의미를 살펴보며 포스팅을 마치겠다. 자글자글하며, 빠르게 변하는 excitation신호가 vocal tract filter를 통과해서 speech가 되는 것인데, 이렇게 빠르게 변하는 부분을 smoothing하는 효과를 주어 spectral envelop을 구할 수 있게 되고 이는 vocal tract특성을 나타내는 부분만 추출했다고 볼 수 있게된다.
formant는 peak 3개 정도 보면 되고 f0, f1, f2라고도 부른다.
Reference
Theory-and-Applications-of-Digital-Speech-Processing (Rabiner Schafer)
'Domain Knowledge > Speech' 카테고리의 다른 글
| Normalized log mel-spectrogram의 python 구현 (0) | 2020.08.03 |
|---|---|
| MFCC(Mel Frequency Cepstrum Coefficient)의 python구현과 의미 (2) | 2020.08.03 |
| Pitch detction(ACF, AMDF, Cepstrum) (0) | 2020.07.31 |
| Speech production and perception(음성의 생성과 인지) (0) | 2020.07.31 |
| 음성신호처리에서 frame 생성시 overlap을 하는 이유 (5) | 2020.07.30 |



