MFCC의 python 구현
python의 librosa 라이브러리를 이용해 쉽게 구현할 수 있다.
import matplotlib.pyplot as plt
import librosa.display
import librosa
import numpy as np
path = 'sample1.wav'
sample_rate=16000
x = librosa.load(path,sample_rate)[0]
S = librosa.feature.melspectrogram(x, sr=sample_rate, n_mels=128)
log_S = librosa.power_to_db(S, ref=np.max)
mfcc = librosa.feature.mfcc(S=log_S, n_mfcc=20)
delta2_mfcc = librosa.feature.delta(mfcc, order=2)
plt.figure(figsize=(12, 4))
librosa.display.specshow(delta2_mfcc)
plt.ylabel('MFCC coeffs')
plt.xlabel('Time')
plt.title('MFCC')
plt.colorbar()
plt.tight_layout()
MFCC함수의 파라미터:

입력:
**입력에는 y나 S 둘 중 하나만 들어가면 된다.
- y: time domain audio signal
- sr: sampling rate
- S: log mel-spectrogram
- n_mfcc: mfcc coefficient 개수
- dct_type: 1 or 2 or 3
- norm: 만약 dct type1 이면 ortho로 설정 아니면 없어도댐
- lifter: lifter하면 higher-order 강조 (cepstrum liftering)
출력:
- mfcc: (n_mfcc, time_step)
결과창:


MFCC의 배경
가중치를 갖는 cepstrum의 distance measure는 직접적으로 주파수 도메인에서의 log spectrum distance와 같다. (위에 대한 설명은 아래에 수학적으로 설명할 예정이니 무시해도 좋다.) 이것은 우리 인간의 귀안 특히 내이(inner ear)에서의 일어나는 음성분석(주파수 분석) 관점에서 굉장히 중요하다. 우리는 음성을 분석하고 그 음성의 특징을 뽑아내기 위해서 인간의 행동을 모사하는 경우가 많이 있다. MFCC도 이와 같은 관점에서 나오게 된 것이다. 간단히 말하면 MFCC는 인간이 소리를 인지하는 과정(원리)을 따라 해서 '어떤 특징 벡터'를 추출해내는 과정이다.
인간의 귀속에서도 특히 내이(inner ear)의 기저막은 주파수에 따라 진동하게 되는 부분이 다르다. 이를 통해서 각각 다른 주파수 대역이 진동하고, 소리를 분리해서 인식하게 된다. 이를 모사하기 위해서 MFCC는 Mel filterbank라는 필터뱅크를 이용해서 소리를 주파수 대역별로 걸러낸다.
예를 들어보자.
여러 크기의 돌이 한데 모여있는데 이를 각각의 크기별로 고르고 싶다고 하자. 그렇다면 구멍이 큰 채를 이용하여 큰 돌부터 거를 수 있고 점점 작은 채를 이용하여 작은 돌을 거를 수 있을 것이다. MFCC도 이와 마찬가지이다. 낮은 주파수부터 큰 주파수까지의 필터들을 이용하여, 느리게 변화하는 소리부터 빠르게 변화하는 소리까지 빠르기(즉, 주파수) 별로 걸러낼 수 있는 것이다.
MFCC는 결국 내이의 기저막을 흉내 낸 기법으로 기저막의 원리를 살펴보면 조금 더 쉽게 이해할 수 있지 않을까 싶다.

위의 그림은 기저막을 나타낸 그림이다. 각각 낮은 주파수에서 높은 주파수까지 기저막이 진동하는 부위가 다르고 그 진동은 곧 신호가 되고 신경계에 전달된다. 위와 같은 귀에서 소리를 인식하는 과정, 즉 듣는 과정은 critical band이론으로 설명할 수 있게 된다.
앞에서 쭉 설명했던 내용을 우리가 배웠던 주파 수상에서의 bandpass filter를 이용해서 설명한 것으로 의미는 같다. 다만 추가되는 내용이 있다면, 우리는 낮은 주파수에 더욱 민감하게 반응한다는 것이다. 그러므로 낮은 주파수 대역은 더 세세하게 대역을 나눌 필요가 있다. 그래서 아래 그림과 같이 낮은 주파수에선 더 세세하게, 높은 주파수로 갈수록 듬성듬성 쪼개져있는 것을 알 수 있다.

이것이 critical band를 나타낸 그림이다. 이렇게 쪼개진 filterbank를 이용하여 우리는 소리를 인지한다는 것을 배웠다. MFCC도 필터 뱅크를 이용하여 값을 구하기 때문에, 이 부분을 염두에 두면 조금 더 쉽게 이해가 갈 수 있을 것이다.
MFCC의 의미
MFCC는 음성신호가 가지고 있는 어떠한 특징을 뽑아내는 과정이다.(feature extraction) 이름에서도 알 수 있다시피 coefficient이다. 즉 계수를 뜻한다. 계수가 무엇인가? 푸리에 계수를 떠올려보자. 푸리에 계수는 어떤 주파수에 얼마만큼의 값이 존재하는지, (=exponential기저 신호에 곱해진 값) 그 '얼마만큼의 값들'을 푸리에 계수라 칭했다. MFCC 역시 '어떤 처리를 하여 구한 계수'를 뜻한다. 어떤 처리를 하는지는 뒤에서 다시 살펴보도록 하고! MFCC가 가지는 가장 큰 의미는 아무래도 음성인식에서 가장 흔히 이용되는 파라미터라는 것이다. 이 파라미터는 여러 task(음성을 어떤 식으로든 분류하는 task)에서 음성의 한 feature(특성)으로써 이용될 수 있다.
Mel filterbank란?
그렇다면 Mel Frequency Cepstrum Coefficient에서 Mel이 무엇일까?
Mel은 우리의 주파수에 따른 주관적인 인지량을 측정하는 단위이다. 그니까 쉽게 말하면, 우리는 주파수가 높아지는 만큼 그대로 인지를 잘하는 것이 아니다.(선형적으로 인지하지 않는다.) 인간은 주파수가 너무 높아지면 잘 구별하지 못하는 특성이 있다. 그래서 우리가 주파수를 비선형적인 값으로 mel이라는 단위로 매핑을 시키기로 했다. 그렇다면 mel이라는 단위는 비선형적인 주파수라는 단위를 인간의 특성에 맞게 선형적으로 표현할 수 있게 된다. 기준은 1000Hz이다. 그래서 1000 mel=1000Hz라고 하고 시작한다.
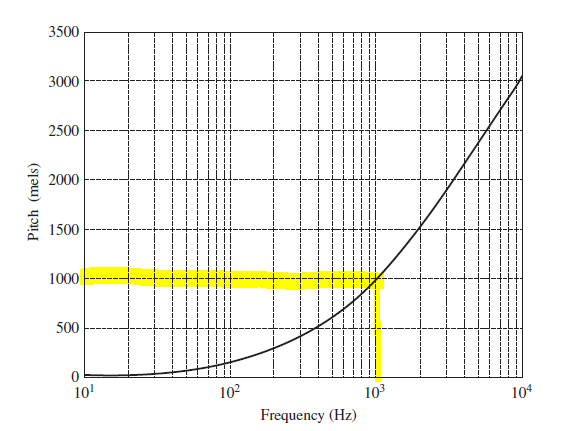
1000Hz를 1000 mel이라고 하고,

다음 로그함수를 이용하여 mel단위의 pitch값을 계산할 수 있다. log함수는 x축 값이 커질수록 y축 변화가 별로 없어진다. 그러므로 이 그래프에서는 주파수가 높아질수록 사람이 인지하는 것은 거의 같다는 것을 알 수 있다.(=둔하게 인지한다.)
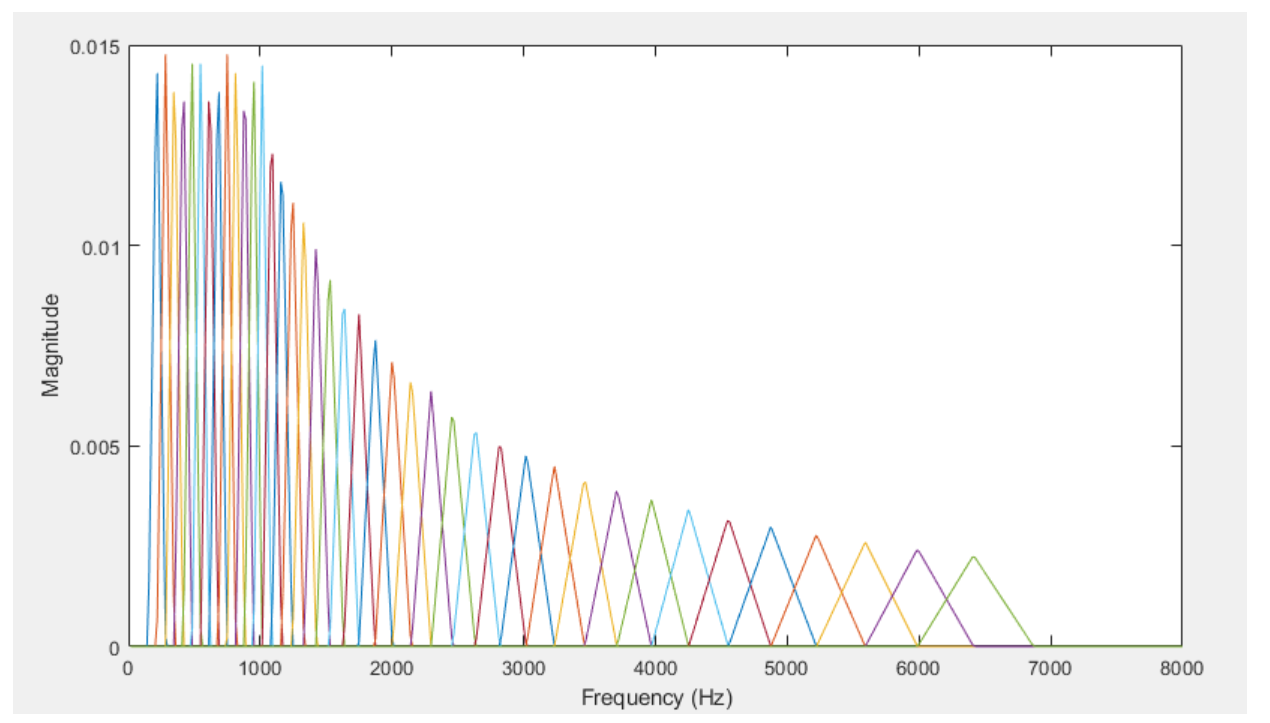
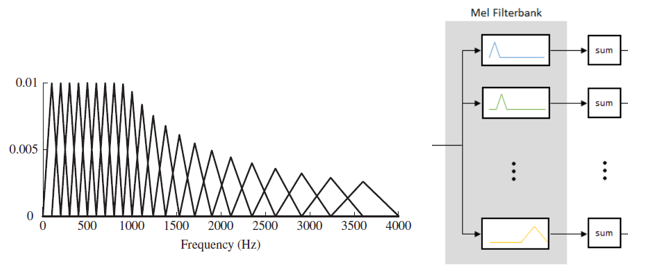
이러한 주파수에 따른 실제 사람의 인지량이라는 Mel단위로 주파수를 쪼갠 필터들을 모았다는 의미에서 Mel filiterbank라는 필터뱅크를 설계할 수 있다. 실제 인간의 critical band에 근사하게 이 필터를 설계했고 아래 그림과 같이 4kHz의 bandwidth를 대략 20개의 overlap 된 필터로 나누었다. 그리고 각각의 필터는 다른 weight를 갖고(y축을 보면 값이 다 다르다!) triangular function의 형태를 가진다.
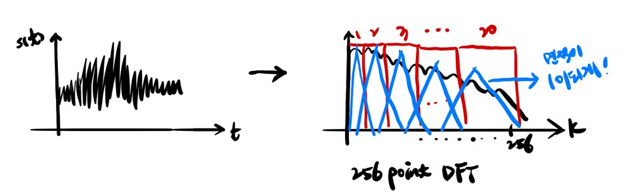
실제 time-domain signal을 DFT 한 표현과 mel filter bank표현과의 연계를 내 발그림으로 보면 아래와 같다.
Mel filter의 개수는 어떻게 정하는가?
linear-bark conversion으로 대략적인 필터수에 따른 center frequency를 나타낸 그래프인데, 대략 8kHz의 샘플링을 한 신호의 경우 20개 정도의 필터가 필요하다는 것을 알 수 있다.

MFCC를 구하는 과정
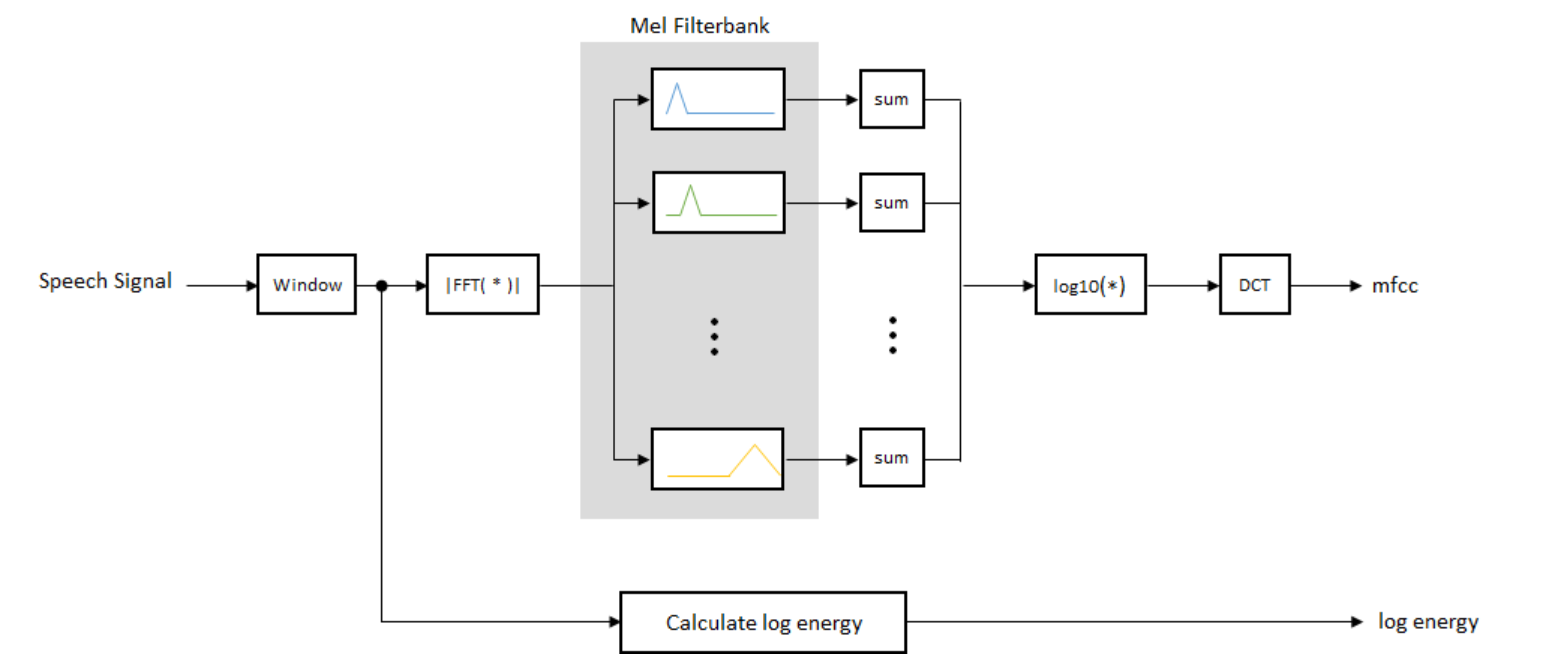
단계를 하나씩 살펴보자.
1. Pre-emphasis filtering
음성이 고주파 부근에서 크기가 작아지는 특성이 있기 때문에 전처리를 통해서 이를 강조해줄 수 있다. 이를 통해서 주파수 스펙트럼의 밸런스를 맞출 수 있다. pre-emphasis filter 식은 아래와 같이 정의할 수 있다.

알파 값은 0.95 또는 0.97로 잡을 수 있다. pre-emphasis을 cepstral mean normalization과정으로 대체할 수 있어 굳이 안해도 된다.
2. Windowing
음성신호는 non-stationary 하기 때문에 전체를 FFT하지 않는다. 그래서 frame단위의 처리를 하게 되는데, frame길이는 25~35ms를 주로 사용하고 50% overlap을 이용할 수 있다.
3. FFT & magnitude spectrum
실제로 구현을 하기 위해서는 DFT를 수행하고, Xm[k]를 구할 수 있다. (m번째 frame의 DFT값) FFT알고리즘을 이용해서 빠르게 계산할 수 있고 N-point DFT에서 N은 256 혹은 512를 주로 사용. 아래 첨자가 frame number가 된다 그래서 아래의 식은 1번째 frame의 DFT계수들
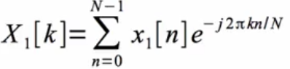

위와 같이 N개(256개+1개(DC) = 257개)의 coefficient가 각 frame마다 나오게 된다.
4. Mel-filterbank
8kHz일 때 주로 mel-filter의 개수 R=24인 mel-filterbank를 이용할 수 있다.
그래서 m번째 frame의 DFT값인 Xm[k]를 Mel filterbank Vr[k](R=24)에 통과시킨다. 그러면 필터개수(24개)만큼의 값이 나오게 된다. 식은 다음과 같이 쓸 수 있다.
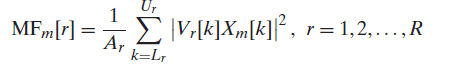
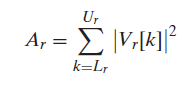

의미를 해석해보면, Vr[k]는 저 필터뱅크들 중에 r번째 필터뱅크를 주파수축에서 나타낸 식이다. Xm[k]를 r번째의 필터뱅크에 통과시켜서(주파수상에서의 곱으로 나타남) 제곱한 것(energy를 구하기)을 합한다.
→각 필터에 해당하는 신호의 에너지를 합하는 과정
그러면 m번째 frame에 대해 r번째 필터뱅크에 대한 에너지값이 r=1~R까지 MFm[r]에 각각 저장된다. 여기서 1/Ar은 normalizing factor가 되겠다.
5. log() & IDCT => MFCC
이 과정에서는 log를 취하고 IDCT연산을 하게 된다. 원래 cepstrum이라면 IDFT과정을 거쳐야하지만, 여기선 IDCT를 하게된다. (DCT와 IDCT는 앞에 normalizing factor만 다르고 연산과정은 같으므로 IDCT로 표기할 수도 DCT로 표기할 수도..) DCT는 exponential의 real part만 취한 변환으로 energy compaction의 장점이 있다.
의문을 가질 수 있는 부분은, cepstrum이라고 해놓고 왜 IDFT과정이 없고 DCT를 하느냐? 이다. DCT는 KL transform과 긴밀하게 연관되어있다. KL transform은 PCA의 기반이다. 이는 높은 차원의 데이터를 orthogonal하게 projection 시킨다. 그러므로 결과적으로 DCT는 mel-frequency log energy decorrelate(약간 분해하는 느낌으로 이해)하는 경향이 있다. DFT→log→IDFT과정을 homomorphic analysis중 특별 케이스로 보지만, MFCC는 IDFT과정이 없기 때문에 homomorphic으로 보기 어려울 것이다.
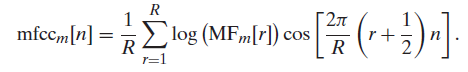
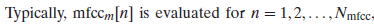
여기서 Nmfcc는 mel-filter 수보다 작게 설정한다. 아래의 그래프는 한 frame에 대해서 각각 STFT, LPC, MFCC 등의 방법을 이용해서 계수를 구해서 비교한 그래프이다. 이때, MFCC의 파라미터는 mel-filter 수 R=24, Nmfcc=13로 설정하였다.
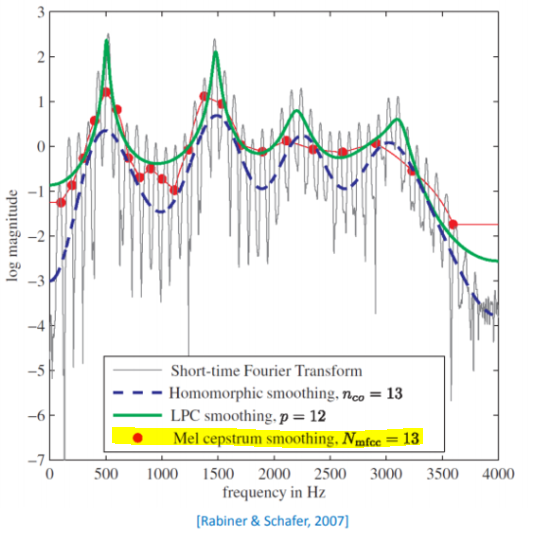
그림의 빨간 점 같은 경우, log(MFm[r])의 값을 나타내고 이어진 선은 그들 사이를 원래 DFT주파수에 대해 interpolation한다. 이를 보면 MFCC가 음성의 excitation을 효과적으로 제거해 (smoothing을 잘한다) 음성특성을 잘 표현한다는 것을 알 수 있다. 이 그래프를 통해서 공통적으로 vocal tract(성도)의 특징인 formant frequency를 판별할 수 있다. 그러므로 MFCC가 음성을 잘 표현하면서 데이터양이 적은 feature vector로 사용될 수 있음을 알 수 있다. 하지만 요즘은 연산장비가 워낙 좋아 MFCC를 사용하지 않고 mel spectrogram을 사용해도 무리가 없고 더 풍부한 표현을 학습하기에도 좋다.
Reference
https://zinniastop.blogspot.com/2017/12/mfcc.html
https://kr.mathworks.com/help/audio/examples/speaker-identification-using-pitch-and-mfcc.html
http://research.cs.tamu.edu/prism/lectures/sp/l9.pdf
librosa.org/doc/latest/generated/librosa.feature.mfcc.html?highlight=mfcc
'Domain Knowledge > Speech' 카테고리의 다른 글
| 다채널 음성인식을 위한 Multi-channel speech processing(Spatial information/ Beamformer) (0) | 2020.08.04 |
|---|---|
| Normalized log mel-spectrogram의 python 구현 (0) | 2020.08.03 |
| LPC(Linear Prediction Coding, 선형예측부호화)와 formant estimation (0) | 2020.07.31 |
| Pitch detction(ACF, AMDF, Cepstrum) (0) | 2020.07.31 |
| Speech production and perception(음성의 생성과 인지) (0) | 2020.07.31 |



